Guida alla fotografia digitale
Guida alla fotografia digitale
Questo sito utilizza cookie, anche di terze parti. Se vuoi saperne di più leggi la nostra Cookie Policy. Scorrendo questa pagina o cliccando qualunque suo elemento acconsenti all’uso dei cookie.I testi seguenti sono di proprietà dei rispettivi autori che ringraziamo per l'opportunità che ci danno di far conoscere gratuitamente a studenti , docenti e agli utenti del web i loro testi per sole finalità illustrative didattiche e scientifiche.
Grafica Vettoriale e Grafica Bitmap
Le immagini digitalizzate, come ogni altro tipo di dato, quando vengono salvate su disco, sono memorizzate in un file. La maggior parte dei programmi per la grafica, è oggi in grado di salvare immagini in formati diversi ( PCX, TIF, BMP, JPEG,... ) sebbene esistano moltissimi differenti formati, le immagini possono essere sempre classificate in due grandi categorie: le immagini bitmap gestite da programmi di grafica pittorica (paint) e le immagini vettoriali gestite dai programmi di grafica vettoriale (draw).
In una immagine tipo bitmap i pixel sono gli elementi che costituiscono l'immagine stessa anche nella sua rappresentazione interna infatti il file dell'immagine contiene per ciascun pixel informazioni relative alla sua posizione ed al suo colore. Il numero dei pixel di un'immagine ne determina la qualità: quanto maggiore è il numero di pixel, tanto meglio è definita l'immagine.
Il formato a punti è eccellente per dare un'illusione di transizione graduale fra i colori, il che lo rende migliore per le foto e le immagini realistiche. Lo svantaggio di questo tipo di immagine è che:
occupano molto spazio
quando si devono fare ingrandimenti, l'immagine perde di qualità formando i tipici bordi a zig zag.
In un file che contiene un'immagine vettoriale gli elementi che compongono l'immagine sono definiti mediante formule matematiche. Un quadrato, per esempio, sarebbe descritto in termini dell'area che copre, della lunghezza e dello spessore delle sue linee, dalla sua posizione e cosi via.
Un file così strutturato occupa ovviamente molto meno spazio rispetto ad un file in formato bitmap. L'immagine, per essere visualizzata o stampata, viene ricostruita in base alla descrizione presente nel file.
Le immagini vettoriali sono composte da linee e figure descritte in termini di algoritmi matematici, perciò possono essere ingrandite o deformate senza che si creino linee a zig zag, inoltre esse occupano poco spazio. Il loro svantaggio è che sebbene siano eccellenti per le riproduzione a colori, non sono altrettanto valide per i dettagli più minuti o per la riproduzione di transizioni di colore graduale.
BITMAP O VETTORIALE? I due tipi di immagini digitali
Le immagini che vengono elaborate dal computer si dividono fondamentalmente in due grandi categorie: immagini vettoriali e immagini bitmap (o raster).
La differenza tra i due tipi non è necessariamente visibile, piuttosto risiede nel modo in cui sono "descritte", cioè nel linguaggio che viene usato per codificarle. Le immagini vettoriali vengono descritte in termini di funzioni matematiche, quelle bitmap - come suggerisce la stessa denominazione - sono invece "semplici" mappe di bit. Semplificando, possiamo dire che una linea retta nera in formato vettoriale verrà descritta da una formula che, volgarizzando, suonerà più o meno così: dal punto (x,y) parte una linea di colore nero che termina al punto (x,z). La stessa linea retta in formato bitmap avrà una descrizione che suonerà invece così: il punto (x,y) è nero, il punto (x,a) è nero, il punto (x,b) è nero... e così via, fino al raggiungimento del termine della linea: viene cioè descritta la dislocazione di tutti i singoli punti che costituiscono l'immagine, con il loro relativo valore di colore.
Questa differenza nel linguaggio di codifica si ripercuote sulle caratteristiche e sulle potenzialità delle immagini.
Il formato vettoriale, ad esempio, si presta ad essere utilizzato soprattutto nel disegno tecnico e nella grafica editoriale, nei settori, cioè, in cui le immagini non devono necessariamente avere caratteristiche fotografiche, quali ricchezza di sfumature e generali proprietà di realismo: la descrizione matematica di sfumature fotorealistiche, infatti, può richiedere elaborazioni particolarmente complesse, annullando così uno dei principali vantaggi delle immagini vettoriali, vale a dire la loro "leggerezza" in termini di byte.
L'effetto di fotorealismo è invece facilmente ottenuto dalle immagini bitmap: qualsiasi sfumatura di colore può ormai essere pienamente risolta da un'immagine di questo tipo e i continui progressi nel settore permettono di raggiungere risultati sempre più indistinguibili da quelli ottenuti con i tradizionali mezzi fotografici. Naturalmente, le immagini bitmap sono più "pesanti" in termini di byte, nonostante siano stati elaborati diversi algoritmi di compressione che permettono "snellimenti" anche molto cospicui.
Un'altra differenza essenziale tra i due tipi di immagine riguarda il loro comportamento nel caso di operazioni ridimensionamento. Le immagini vettoriali possono essere ingrandite a piacimento senza che questo influisca sulla loro qualità; le immagini bitmap, per contro, se ingrandite, perdono inevitabilmente in qualità, mostrando, in modo più o meno evidente, una tipica "quadrettatura". Ciò è dovuto al fatto che mentre le funzioni matematiche che descrivono un'immagine vettoriale possono essere semplicemente ricalcolate per adeguarsi alle nuove dimensioni dell'immagine, soltanto un'operazione di interpolazione - che per quanto accurata non può che essere approssimativa - permette di creare nuove informazioni relative a punti della mappa di bit prima inesistenti. Un modo più "tecnico" di illustrare questa situazione consiste nell'affermare che mentre la risoluzione (la "quantità di dettaglio") di un'immagine bitmap è dipendente dalle sue dimensioni, quella di un'immagine vettoriale non ne è influenzata.
RISOLUZIONE
Come abbiamo appena accennato, la risoluzione rappresenta la quantità di dettaglio presente in un'immagine e si misura generalmente in DPI ("dot per inch"), vale a dire in "punti per pollice": un'immagine con una risoluzione di 300 DPI, ad esempio, apparirà più dettagliata (più definita) di una a 150 DPI, in quanto ogni pollice quadrato della sua superficie è composto da un numero di punti molto più elevato (ognuno dotato di specifiche caratteristiche di colore e luminosità) rispetto alla seconda immagine. Naturalmente, però, un'immagine a 300 DPI, essendo composta di più punti rispetto ad una a 150 DPI, necessita per essere "descritta" di un maggior numero di informazioni, e questo si ripercuote direttamente sul suo "peso" in termini di byte (o di "occupazione di spazio di memoria"). È quindi importante regolare la risoluzione dell'immagine in funzione dell'utilizzo che se ne vuole fare: se ad esempio si vogliono archiviare delle fotografie per poterle visualizzare successivamente sul computer, o per integrarle in un sito internet, una risoluzione di 72 DPI è perfetta, in quanto coincide con la risoluzione alla quale lavorano generalmente i monitor, se invece si intende utilizzare l'immagine per una stampa tipografica, allora la risoluzione deve essere regolata ad almeno 300 DPI, in quanto una risoluzione di molto minore darebbe come risultato un'immagine "sgranata" e fastidiosamente poco definita.
PROFONDITÀ DI COLORE
La profondità di colore rappresenta il numero di colori utilizzati nell'immagine. Un'immagine può infatti utilizzare da un minimo di due (bianco e nero, ad esempio) fino a miliardi di sfumature di colori. Correntemente la profondità di colore viene indicata con il numero dei "bit" (le unità di informazione) necessari per descrivere il corrispondente numero di colori. Ad esempio, una profondità di colore pari a 1 bit, determina un'immagine a 2 colori; una profondità pari a 2 bit genera un'immagine a 4 colori; 3 bit descrivono 8 colori e così via, raddoppiando sempre il numero di colori per ogni bit aggiunto: 8 bit rendono un'immagine a 256 colori (si tenga conto che per "colori" si intendono diversi "valore di colore": 256 colori ad esempio, sono quelli generalmente contenuti nelle immagini in scala di grigio: in questo caso i 256 "colori" sono in realtà 256 tonalità di grigio...), mentre per un'immagine "true color" (a 16 milioni di colori - circa) sono necessari 24 bit (attualmente i software permettono di lavorare con immagini anche a 32 o addirittura 48 bit, ma per la maggior parte degli utilizzi, i 24 bit del "true color" sono certo più che sufficienti...).
Naturalmente, anche la profondità di colore influisce direttamente sulle dimensioni in byte dell'immagine, e va quindi attentamente valutata preventivamente in funzione del tipo di lavoro che si sta compiendo; sarà assolutamente sconsigliabile, ad esempio, mantenere a 24 bit un'immagine in bianco e nero o a scala di grigi, mentre questi 24 bit saranno preferibili agli 8 nel caso si debba produrre un'immagine fotorealistica, in quanto 16 milioni di colori assicurano una resa delle sfumature senz'altro migliore che non 256...
ANTI-ALIAS
Sono dette anti-alias le procedure che permettono di "ammorbidire" i contorni delle immagini digitali. Un contrasto troppo accentuato tra i bordi dell'immagine e lo sfondo sottostante può produrre uno sgradevole effetto di "seghettatura", sia a monitor che in fase di stampa; l'applicazione di specifici filtri in dotazione con i principali programmi di grafica, permette di ovviare a questo problema agendo sulle tonalità di colore dei pixel che costituiscono le aree di maggior contrasto, conferendo loro un aspetto più "sfumato".
Una fotocamera digitale è una macchina fotografica che utilizza, al posto della pellicola fotosensibile, un sensore (CCD, CMOS) in grado di catturare l'immagine e trasformarla in un segnale elettrico di tipo analogico. Gli impulsi elettrici vengono convertiti in digitale da un convertitore A/D nel chip di elaborazione e trasformati in un flusso di dati digitali atti ad essere immagazzinati in vari formati su supporti di memoria.
Una fotocamera digitale è in quasi tutti gli aspetti esattamente identica ad una macchina fotografica convenzionale, se non per il fatto che invece della pellicola fotografica in rullino usa un sensore elettronico che può essere di diversi tipi. Questo converte l'immagine in una sequenza di informazioni digitali che adeguatamente elaborate andranno a formare un file (archivio).
Per questo motivo si rimanda all'articolo sulle macchine fotografiche per ogni informazione concernente lo strumento in sé. In particolare, per le macchine digitali vale come per quelle analogiche, e con lo stesso significato, la distinzione fra fotocamera compatta e reflex. Vi sono comunque formati di fotocamera chiamati “prosumer” (dalla fusione di due termini “professional” e “ consumer”) o anche chiamati “SLR-like” (SLR sta per Single-Lens Reflex – nome tecnico delle macchine fotografiche REFLEX) che hanno caratteristiche funzionali e di qualità immagine estremamente vicine, o a volte superiori alle fotocamere reflex digitali di fascia bassa, pur avendo un obiettivo fisso come le compatte. All'inconveniente dell'ottica non intercambiabile alcuni produttori hanno ovviato introducendo in commercio fotocamere SLR-like con ottiche zoom con ampia escursione focale (da 28 mm equiv. fino a 400 mm equiv.) benché la qualità intrinseca di queste ottiche non possa raggiungere quella delle ottiche di maggior prestigio dedicate agli usi professionali. La presenza di un obiettivo fisso rende dunque sicuramente meno flessibile l’uso della fotocamera in contesti applicativi diversi, ma in positivo c’è da registrare che il fatto che non esponendo l’interno della fotocamera (e quindi il sensore) all’aria durante il cambio di obiettivo, si evita l’accumulo di polvere sul sensore, fatto questo che porta ad avere un degrado della qualità delle immagini riprese.
Forma commerciale delle fotocamere
Ad oggi vengono prodotte fotocamere di ogni forma e dimensione: alcune assomigliano a videocamere, altre sono piccolissime e molto sottili tanto da entrare in un taschino senza essere viste. Vi sono prodotti con "case" in metallo o in plastica, colorate o trasparenti ed il gusto di ogni cliente può trovare soddisfazione in una accurata ricerca. È molto utile prendere in considerazione anche le caratteristiche ottiche ed elettroniche dei prodotti che variano di molto in base alla marca e ai modelli presenti sul mercato.
Risoluzione
Secondo le regole attuali di mercato un parametro distintivo delle fotocamere digitali è quello della risoluzione. Per ottenere una buona fotografia non occorre in realtà una risoluzione altissima, ma risulta essere molto più importante un'ottica di qualità, un sensore che abbia un buon rapporto segnale rumore, una buona gamma dinamica ed infine in funzione delle esigenze di stampa si sceglierà il numero di pixel del sensore.
Il sensore
Il sensore, analogo a quello utilizzato nelle videocamere portatili, può essere CCD, ma anche C-MOS. Sempre comunque si tratta di dispositivi formati da elementi fotosensibili a semiconduttori in grado di trasformare un segnale luminoso in un segnale elettrico. Solo successivamente un secondo dispositivo, funzionalmente separato, (il convertitore Analogico/Digitale) converte il segnale analogico in dati digitali. Nella fotocamera digitale, l'immagine viene messa a fuoco sul piano del sensore. I segnali così catturati vengono amplificati e convertiti in digitale. A questo punto i dati digitali sono in forma grezza (RAW) e - così come sono - possono essere memorizzati su un file per una successiva elaborazione in studio, con altri apparecchi informatici. Successivamente il processore di immagine interno alla fotocamera trasforma questi dati, cioè calcola le componenti primarie mancanti su ogni pixel (RGB) e rende compatibili i dati di immagine con i normali sistemi di visualizzazione di immagini (generalmente nel formato JPG o TIFF a seconda delle esigenze per le quali è destinata la fotocamera) ed infine immagazzina il file elaborato in una memoria a stato solido (ordinariamente dal punto di vista tecnologico si tratta di EEProm di tipo Flash, mentre i formati con cui sono messe in commercio sono diversi (CF, XD, SD, MMC, Memory stick, ecc). Le schede contengono generalmente un rilevante numero di immagini, la quantità dipende dalle dimensioni della singola immagine, dalla modalità di registrazione e dalle dimensioni della memoria.
La risoluzione totale del sensore si misura in milioni di pixel totali. Un pixel è l'unità di cattura dell'immagine: rappresenta cioè la più piccola porzione dell'immagine che la fotocamera è in grado di catturare su una matrice ideale costruita sul sensore CCD.
Le proporzioni delle immagini che si ottengono con gli attuali sensori (o attraverso elaborazioni del processore d'immagine interno alla fotocamera), sono indicate nella figura seguente:
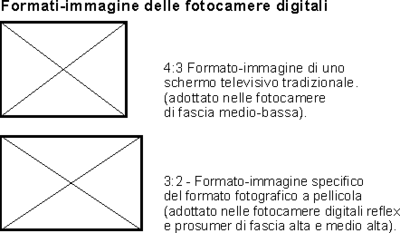
Moltiplicando il valore in pixel della risoluzione orizzontale per quello della risoluzione verticale si ottiene il numero totale di pixel che la fotocamera è in grado di distinguere in una immagine. Le caratteristiche che attribuiscono qualità ai sensori sono:
Elevato rapporto segnale rumore. Questo fenomeno si evidenzia in modo particolare nelle riprese a bassa luminosità dove possono comparire degli artefatti di immagine dovuti a segnali derivanti dal rumore elettrico di fondo degli elementi fotosensibili;
Elevata gamma dinamica. Questo parametro indica l'ampiezza dell’intervallo di luminosità dal minimo registrabile al massimo registrabile prima che l’elemento fotosensibile vada in saturazione.
Elevato numero di pixel. L’elevata quantità di elementi fotosensibili garantisce un elevato dettaglio di immagine, ma sorgono problemi di velocità nel trasferimento dei dati al processore d’immagine. Maggiore è la risoluzione, maggiore è il numero di pixel, maggiore sarà quindi la quantità di dati da trasferire e dunque, a parità di velocità di trasmissione, maggiore sarà il tempo necessario a trasferire i dati al processore d’immagine e la successiva registrazione dell’immagine. Alcuni produttori hanno studiato sensori con 4 bus dati di uscita dal sensore che trasmettono in parallelo i dati di immagine al processore della fotocamera.
Capacità di non trattenere ombre sul sensore relative a riprese precedenti. Questo problema si incontra prevalentemente nei sensori di tipo CMOS e richiede che i costruttori adottino strategie per ottenere una sorta di cancellazione elettronica del sensore fra la ripresa di un'immagine e l'altra;
Capacità del sensore di non produrre artefatti derivanti da interferenze (effetto Moiré) fra i pixel in particolari condizioni di ripresa;
Dimensione fisica del sensore a parità di pixel (e quindi a parità di risoluzione). Se la dimensione fisica del sensore è elevata a parità di numero di pixel questo comporta ovviamente una maggiore dimensione fisica dei pixel o dei photosite (per un chiarimento sui termini photosite, pixel e elemento fotosensibile vedi il paragrafo "Numero di Pixel e qualità delle immagini" della voce correlata Fotografia digitale). Tale fatto rende maggiormente sensibili gli elementi dei photosite (pixel) garantendo un miglior rapporto segnale/rumore. Ad esempio vi sono sensori da 6 MP (f.to 4:3) con dimensione 1/2,7” che hanno una dimensione di 5,371 mm x 4,035 mm (diagonale = 6,721 mm), mentre altri sensori da 6 MP hanno dimensioni 1/1,8” e dimensione di 7,176 mm x 5,319 mm (diagonale = 8,933 mm). In termini di rumore e di sensibilità la qualità del sensore è normalmente maggiore nel sensore più grande.
I sensori di alcune fotocamere REFLEX professionali hanno il sensore di formato 3:2 ed un rapporto 1:1 con il fotogramma della pellicola, una dimensione quindi di 24x36 mm. Con queste dimensioni – oltre ad avere un basso rumore, risulta possibile garantire che la lunghezza focale delle ottiche non sia alterata (rapporto 1:1 fra lunghezza focale reale della fotocamera con sensore e quella equivalente al formato pellicola).
La qualità dell'immagine tuttavia è importante relativamente alla modalità di fruizione: se le immagini si utilizzano a video non ha molta rilevanza la risoluzione, ma se si intendono realizzare stampe di grande formato allora la risoluzione diventa un parametro da tenere presente. Tanto più si vorrà effettuare una stampa grande di una foto digitale, tanto più la fotocamera dovrà produrre immagini ad una risoluzione elevata. Ecco alcuni esempi:
Una foto in formato standard da 14 cm di larghezza necessita di 1.2-2 megapixel di risoluzione per risultare pari ad un prodotto di una macchina fotografica tradizionale;
Per stampare su di un foglio A4 sono necessari dai 2 ai 3 megapixel;
Per realizzare un poster da 60-70 cm sono consigliabili risoluzioni non interpolate di più di 5 megapixel;
Altro parametro a cui andrebbe rivolta una certa importanza da chi della fotografia vuol fare qualcosa più di un hobby è la questione dell'Interpolazione. Tale tecnica matematica viene infatti utilizzata in due modalità diverse a volte contemporaneamente sulla stessa fotocamera:
nelle fotocamere a bassa risoluzione si utilizza per generare dei pixels ulteriori a quelli catturati dal sensore generandone il valore di cromia per portare ad esempio una risoluzione di una fotocamera da 3 Mpixel a 4 Mpixel. Il procedimento in realtà non aggiunge informazioni vere all’immagine, ma rende meno evidente la quadrettatura dovuta al pixel se si volesse ingrandire l’immagine oltre il consentito. È un procedimento usato anche negli scanner attraverso una elaborazione software.
In tutte le fotocamere che adottano un sensore con Color Filter Array si usa l’interpolazione per generare in ogni pixel le due componenti cromatiche mancanti, in questo caso si tratta propriamente di interpolazione cromatica.
In merito a quest'ultima modalità infatti va detto che il sensore - composto da milioni di elementi fotosensibili - solo nel suo complesso cattura informazioni riguardanti le tre componenti RGB (Red-Green-Blue)(Rosso-Verde Blu) che compongono la luce della scena focalizzata sulla sua superficie. Nella quasi totalità dei sensori (anche se con modalità diverse) non tutti i pixel catturano la stessa componente cromatica della luce. Sulla superficie del sensore infatti è collocato un filtro a mosaico denominato Color Filter Array (CFA), il più diffuso è di tipo Bayer che a sua volta può presentare diverse varianti sul numero dei colori che vengono filtrati (3 o 4) e sulla disposizione dei colori sul mosaico. Il più comune è quello denominato GRGB che ha il 50% dei pixel che catturano il Verde (G), il 25% che catturano il Rosso (R) ed il rimanente 25 % che catturano il Blu (B). Per ottenere una adeguata fedeltà cromatica dell’intera immagine, ogni pixel registrato in un file (fa eccezione il file di tipo RAW) deve contenere le informazioni su tutte e tre le componenti RGB della luce incidente su ogni pixel. Questo perché la riproduzione delle immagini luminose avviene per mescolanza additiva delle tre componenti primarie della luce. Poiché ogni pixel ne cattura solo una di queste (R, G o B), le altre due vengono calcolate dal processore d’immagine attraverso un procedimento matematico (algoritmo di demosaicizzazione – demosaicing).
Diversamente da quello che avviene per. es. in alcuni scanner ed in alcune fotocamere dove:
l’interpolazione serve ad aumentare in modo artificiale il numero di pixel senza che vi sia riferimento a nessun oggetto reale;
e nei quali la risoluzione vera è quella ottica, non quella ottenibile via software,
nelle fotocamere digitali il processo interpolazione cromatica comune a tutte quelle dotate di CFA consiste nel calcolare il valore delle due componenti cromatiche mancanti su ogni pixel a partire normalmente dai valori contigui al pixel in questione aventi la stessa componente cromatica che si intende calcolare. L’approssimazione – peraltro abbastanza precisa - è quindi sul dettaglio cromatico dell’immagine e si consideri che comunque una delle tre componenti è realmente rilevata da ogni pixel. Al momento in commercio risulta esservi un solo sensore, il FOVEON, che cattura le tre componenti RGB su un unico pixel (che più propriamente si deve chiamare photosite). Questo viene montato su alcuni modelli di fotocamere, ma la sua diffusione è più ridotta rispetto ai sensori dotati di C.F.A. Una precisa distinzione fra pixel, photosite e elemento unitario fotosensibile=photodetector) si trova nel paragrafo Numero di Pixel e qualità delle immagini della voce correlata fotografia digitale. Invece un approfondimento sulle diverse modalità di formazione delle immagini nelle fotocamere digitali, sulla formazione dei file delle immagini per interpolazione in base alle esigenze di profondità colore e sulla elaborazione dei files RAW, si trova alla voce Raw (fotografia)
Le memorie
Una volta convertito il segnale in arrivo dal sensore (CCD o C-MOS) ed elaborato dal processore d’immagine, la fotocamera registra un file contenente l'immagine scattata su una memoria gestibile dall'utente. Alcune fotocamere economiche dispongono di una memoria interna di salvataggio immagini, alla quale normalmente è sempre possibile aggiungerne una esterna.
Dal punto di vista tecnologico - quel punto di vista che specificamente si occupa di conoscere la modalità di immagazzinamento dei dati elementari su un supporto di memoria - va detto che il tipo di memorie prevalentemente usato è di tipo EEPROM flash (Electrically Erasable and Programmable Read Only Memory - flash). La tecnologia "flash" consente di accedere alle celle di memoria per blocchi, o aree, rendendo più rapido il processo di lettura-scrittura-cancellazione). Per questo occorre distinguere fra la tecnologia costruttiva degli elementi di memorizzazione (per tutte le schede di memoria si tratta, come visto, di EEPROM-flash) e i formati con cui vengono prodotte le schede di memoria. I formati di scheda di memoria realizzati con celle a semiconduttore utilizzati dalle case costruttrici di fotocamere digitali, sono principalmente:
Compactflash
Compactflash Extreme III
Compactflash Ultra
Compactflash Ultra II
Compactflash Ultra Speed
Memory Stick
MultiMedia (MMC)
SD (secure digital)
mini-SD
TransFlash (o micro-SD)
SmartMedia
XD - xD tipo M - xD tipo H (foto panoramiche per le Olympus e Fuji)
 Vi sono poi schede di memoria come la seguente:
Vi sono poi schede di memoria come la seguente:
Microdrive
le quali non sono riconducibili a celle a semiconduttore, bensì a supporti magnetici dello stesso tipo degli hard disk dei PC, ma che per contro adottano lo stesso formato delle memorie a semiconduttore. Nel caso delle Microdrive il formato è quello delle C.F. CompactFlash
Invece altri formati, inoltre, come il:
miniCD-ROM fanno riferimento ad un supporto ottico di memorizzazione (mini-CD). Tecnica di memorizzazione oggi sostanzialmente abbandonata, ma che prevedeva nelle fotocamere l'incorporazione di un masterizzatore per mini-CD.
Un elenco completo può essere trovato alla voce Scheda di memoria.
I formati di salvataggio delle immagini
I formati utilizzati nelle fotocamere digitali per il salvataggio delle immagini sono:
JPG: il più usato nelle fotocamere economiche. Permette di salvare grandi immagini in file di piccole dimensioni, pur perdendo dettagli all'occhio impercettibili ma che rischiano di diventare evidenti in caso sia necessario effettuare successive manipolazioni di (fotoritocco) all'immagine salvata. Si tratta di un formato compresso di tipo LOSSY, ovvero con perdita di dati.
TIFF: formato in grado di salvare immagini senza perdita di informazioni. Il salvataggio può essere non compresso o compresso di tipo LOSSLESS. Si può osservare come questo formato, se si sfrutta la compressione, produca immagini identiche alle BMP ma della dimensione di una BMP compressa con ZIP.
BMP: formato di salvataggio poco utilizzato, per via del fatto che il file è di dimensioni piuttosto elevate. Le immagini possono essere salvate a 16, 24 e 32 bit senza nessun tipo di compressione.
RAW: formato utilizzato dai professionisti e dai fotoamatori evoluti. Una fotocamera settata per salvare il formato RAW di una istantanea salverà nella memoria utente esattamente l'output digitalizzato ottenuto dal sensore della fotocamera stessa, senza alcun tipo di modifica se non la conversione Analogico/Digitale (conversione A/D). I dati dovranno essere quindi ricomposti su un computer secondo specifici protocolli della casa madre definiti per lo specifico sensore utilizzato. Solo successivamente le immagini così ricomposte ed eventualmente regolate in luminosità ed altro, saranno convertibili ed utilizzabili in qualsiasi formato conosciuto.
Vantaggi dei files RAW
Quale è dunque il grande vantaggio del RAW? Il motivo principale va ricercato nella modalità di registrazione del file e nelle possibilità di elaborazione che esso offre successivamente allo scatto. Un file RAW durante la conversione da analogico a digitale è normalmente campionato almeno a 12 bit per canale (R,G o B). Ognuno dei canali cromatici a questo livello della elaborazione è ancora incompleto avendo solo i segnali raccolti dai photodetectors e non anche quelli generati per interpolazione. Alcune fotocamere di alto livello producono file RAW con campionamento a 16 bpp (bpp=bit-per-pixel o, meglio, bit-per-photodetector) e, come si è visto, questa è una sola delle tre componenti del pixel. I software di elaborazione dei file RAW hanno la possibilità quindi di produrre files grafici RGB a 48 bpp (qui è perfettamente corretto ritenere b.p.p. come bit-per-pixel, perché, quando il file grafico è elaborato, ogni pixel contiene tutte e tre le componenti RGB necessarie per definire ogni elemento del pixel). Per questa elevatissima profondità colore il file si presta ad elaborazioni anche abbastanza spinte senza che la qualità e dettaglio di immagine degradino troppo. Si consideri che normalmente la generazione del file TIFF o del file JPG avviene a profondità colore di 24 bpp (che equivale ad 8 bpp per ognuno dei canali RGB) quindi per la stampa è normalmente richiesto un dettaglio cromatico (=profondità colore) molto minore. Tale caratteristica tecnica dei files RAW permette una lavorazione in studio delle immagini senza alterarne la qualità. Ma non solo. L'utilizzo dei files RAW consente addirittura di apportare in un secondo momento con elaborazioni in studio dei miglioramenti significativi alla qualità dell'immagine scattata, potendo per esempio aggiustare il bilanciamento del bianco, ridurre eventuali aberrazioni cromatiche degli obiettivi, ottimizzare l'esposizione con un campo di variazione abbastanza elevato, applicare filtri antirumore, ecc., ecc.)
È invece secondaria e fuorviante la ragione che vede nel file RAW la possibilità di compiere scatti in rapida successione (chiamata anche "funzione di scatto a raffica" delle fotocamere), anche perché tale funzione delle fotocamere viene svolta molto più rapidamente con altri formati come il JPG. Usando questa funzione infatti la fotocamera ha necessità di tenere in memoria i dati delle immagini scattate nella raffica. Quindi, per questo, occorre integrare nella fotocamera una sorta di memoria di servizio (buffer) dove parcheggiare le immagini prima della loro scrittura nella scheda di memoria. Poiché le immagini JPG, anche se composte in alta qualità, hanno una dimensione di circa 1/4 della stessa immagine in RAW, lo svolgimento di tale funzione non comporta l'impiego di una grande quantità di memoria interna. Quindi tale funzione in JPG è molto frequente trovarla nelle fotocamere anche di fascia medio-bassa. A questo proposito si consideri che il tempo di registrazione dell'immagine nella scheda di memoria è normalmente molto superiore a quello che impiega il processore d'immagine ad elaborare i dati grezzi in arrivo del sensore per formare l'immagine JPG. Dunque, complessivamente, il tempo impiegato dalla fotocamera per svolgere la funzione di scatto a raffica è comunque minore in JPG rispetto al formato RAW.
Nonostante queste caratteristiche della funzione che permette scatti in rapida successione, vi sono fotocamere professionali, semi-pro, e compatte-prosumer di fascia alta, che presentano questa possibilità di registrare immagini in RAW con scatto a raffica. Tale diffusione è stata agevolata dal progressivo calo di costo delle celle di memoria che ha reso economicamente vantaggioso aumentare questa memoria buffer interna alle fotocamere. Questo fatto ha reso disponibile la funzione di scatto in rapida successione anche in fotocamere digitali non professionali che comunque possiedono prestazioni tali da far valutare positivamente tale funzione. Va detto tuttavia che nonostante l'uso dello scatto a raffica non sia così frequente come lo scatto singolo, tale funzione è apprezzata dai professionisti e dai fotoamatori evoluti.
Inoltre tale funzione di scatto a raffica in RAW è conseguenza anche del miglioramento dell'elettronica delle fotocamere che ha reso più veloce le procedure di elaborazione e di trasferimento delle immagini. Nell'utilizzo dei files RAW occorre tenere presente che:
la memorizzazione di un file RAW ha una dimensione elevata dunque richiede più tempo per la sua registrazione nella scheda di memoria. Molto più rapida è la memorizzazione di un file JPG, registrato anche in alta qualià (dimensioni elevate del file). Questo comporta l'effetto finale secondo cui il tempo per registrare un file JPG è molto più basso rispetto a quello necessario per registrare un file RAW. E questo è valido anche se si considera che il processore d'immagine interno alla fotocamera spende un po' più di tempo per la formazione del file JPG a partire dai dati grezzi d'immagine.
nel caso invece dello scatto a raffica (da tre in poi) i dati RAW delle immagini scattate in rapida successione vengono trattenuti in una memoria interna "di servizio" della fotocamera (buffer). Per svolgere questa funzione occorre però dotare la fotocamera di una sufficiente quantità di memoria interna che dovrà essere tanto maggiore quanto maggiore è la dimensione del file RAW e quanto maggiore è il numero degli scatti della raffica.
Il formato RAW è un particolare metodo di memorizzazione dei dati descrittori di un'immagine. Ciò permette di non avere perdite di qualità della registrazione su un qualsiasi supporto rispetto ai segnali catturati dal sensore e successivamente composti per interpolazione dal processore d’immagine della fotocamera nelle sue tre componenti fondamentali RGB (RED, GREEN, BLUE).
La risoluzione massima reale dell'immagine rimane quella determinata dalle caratteristiche del sensore installato nella fotocamera digitale. La metodica RAW è per lo più utilizzata nelle macchine fotografiche Reflex digitali di alto livello, ma anche in quelle compatte di fascia alta, le cosiddette "formato bridge" o "prosumer" (contrazione dei due termini "professional" e "consumer"), o ancora, chiamate "SLR-like" (simile a una Single Lens Reflex).
Il termine inglese RAW - che fra i diversi significati che esso assume, qui interessano quelli che rimandano al concetto di "non elaborato", "non raffinato", "grezzo" - sta ad indicare che l'immagine catturata dal sensore CCD o CMOS della macchina fotografica, viene registrata nella sua forma originaria, numerica, cioè dopo essere stata solo convertita da analogico a digitale, senza nessuna ulteriore elaborazione da parte della fotocamera. Nel formato RAW vengono registrati quindi, i dati monocromatici grezzi indicanti l'informazione di intensità luminosa incidente sui singoli photodetector R, sui singoli photodetector G e sui singoli photodetector B. Questa descrizione è valida nel caso di un sensore con CFA (Color Filter Array) di tipo bayer RGB, mentre nel caso il CFA sia di tipo diverso, ad esempio RGB-E (Red, Green, Blue, Emerald) quadricromatico, l'eventuale file RAW che si forma, conterrà le quattro informazioni monocromatiche separate, derivanti dai photodetector che registrano i quattro colori.
Per questo la registrazione in RAW dà la possibilità di catturare le immagini con una regolazione anche non ottimale di alcune impostazioni (esposizione, bilanciamento del bianco, ecc), in quanto la successiva elaborazione in studio (il cosiddetto "sviluppo in camera chiara") consente di regolare questi parametri di ripresa mantenendo la qualità ai livelli più alti possibile. Ma attenzione: profondità di campo e messa a fuoco devono essere ottimali in fase di ripresa perché la metodica RAW di registrazione non consente di ricostruire dettagli di immagine persi dall’ottica della fotocamera a causa, ad esempio, della mancata messa a fuoco della scena ripresa o di suoi singoli elementi
Una descrizione dettagliata dei file RAW si trova nella voce correlata Raw (fotografia).
NOTA
AVI, MOV, REAL MEDIA: questi formati vengono utilizzati dalla maggior parte delle fotocamere in circolazione per realizzare piccole sequenze video, solitamente di durata mai superiore ai 5 minuti. Tale caratteristica è di facile realizzazione data la natura dell'architettura delle fotocamere digitali, ma non si deve pensare che tali filmati possano essere equiparabili a quelli prodotti da videocamere digitali o analogiche! Le modalità di otturazione, il buffer utilizzato dal CCD e la natura del software della fotocamera non consentono di realizzare nulla più che un filmato adatto ad una pubblicazione web. Sarebbe impensabile registrare un matrimonio con una fotocamera digitale. Tale limitazione ha però vita breve: in alcuni moderni dispositivi è stato predisposto un sistema di codifica tale per cui i filmati vengono direttamente compressi con algoritmi tanto efficienti (anche DivX) da rendere il sistema adatto a registrare filmati di grande durata.
// if (window.showTocToggle) { var tocShowText = "mostra"; var tocHideText = "nascondi"; showTocToggle(); } // Formazione del file immagine
Per una comprensione ottimale delle descrizioni che seguono è utile fare una distinzione concettuale fra pixel, photodetector (da intendere come elemento unitario fotosensibile) e photosite. Per questo si rimanda alla voce correlata Fotografia digitale nella sezione Numero di Pixel e qualità delle immagini.
Il sistema ottico della fotocamera focalizza l'immagine da riprendere sulla superficie del sensore. Questo è formato da milioni di elementi a semiconduttore sensibili alla luce (photodetector). Ognuno di questi è collocato in un photosite (luogo fisico del sensore dove si catturano i dettagli elementari dell'immagine) ed è la base da cui successivamente si formerà il pixel. La superficie è ricoperta dal Color Filter Array il quale ha il compito di separare e distribuire le tre componenti cromatiche su photosites (pixel) diversi del sensore. Nel 50% dei photosite (pixel) arriva la componente verde (G), nel 25% arriva la componente blu (B) e nella stessa quantità del 25% la componente rossa (R). Ad esempio, in un ipotetico sensore di 256 photosite, 128 photosite saranno investiti dalla componente verde della luce della scena ripresa, mentre 64 photosite saranno investiti dalla componente blu e i rimanenti i 64 photosite dalla componente rossa. I filtri sui singoli photosite sono distribuiti in modo omogeneo e geometricamente regolare.
In questo modo ogni photodetector registra il segnale relativo ad una sola componente delle tre RGB che compongono l'immagine. In uscita dal sensore devono confluire i segnali analogici o "R", o "G", o "B" di ogni photodetector che portano le relative informazioni. Precisamente in un sensore da 9 MP nominali, la massima risoluzione possibile è di 3.488 x 2.616 photodetectors (pixels) per un totale di 9.124.608 photodetectors. Vi saranno dunque segnali analogici "R" che riguarderanno le informazioni di 2.281.152 photodetectors, segnali analogici "B" che riguarderanno, anche loro, le informazioni di 2.281.152 photodetectors e segnali analogici "G" che riguarderanno le informazioni di 4.562.304 photodetectors del sensore. Il segnale analogico di ogni photodetector viene campionato a 10, 12, 14 o anche 16 bits così che il segnale che descrive l’intera sua scala di luminosità dal nero al massimo consentito "R", "G" o "B" viene trasformato in un'informazione binaria appunto a 10, 12, 14 o 16 bit. Questo significa che, per ogni photodetector, il numero binario, ad esempio a 16 bit, generato dalla conversione A/D indica un livello di intensità individuato fra 65.536 possibilità, all’interno dell’intera gradazione di luminosità (dal nero al valore massimo luminosità di ogni specifico colore primario "R" o "G" o "B") di quel particolare photodetector.
I segnali analogici in uscita dai photdetectors del sensore dopo la loro conversione in digitale possono andare in due direzioni diverse a seconda della impostazione della fotocamera: o verso il processore d’immagine interno che, attraverso l’algoritmo di interpolazione (demosaicizzazione), ricostruisce le due componenti mancanti su ogni photosite, oppure questi dati “grezzi” possono venire registrati appunto nel file RAW. Usando ancora come esempio un sensore di 3.488 x 2.616 pixels (9 MP nominali), la dimensione minima del file RAW sarà di 18.249.216 byte (8 bit= 1 byte; 1 pixel campionato a 16 bit= 2 byte). Normalmente il file RAW relativo è leggermente più ampio perché esso, oltre alle informazioni digitali, dati sui pixels, contiene anche i codici di formato del file, dati cioè che permettono l'identificazione del file (header) e dunque la sua leggibilità.
Alcuni produttori oltre al Color Filter Array a tre colori (RGB) adottano Color Filter Array che fanno uso anche di altri colori (vedi la Sony con il modello DSC-F828 che usa un filter Array a quattro colori: RGB+E (Rosso/Verde/Blu + Smeraldo[1]). Vi sono poi sensori come i FOVEON che non hanno nessun Color Filter Array, ma adottano una tecnica in grado di recepire le tre componenti RGB necessarie per formare l’immagine direttamente su ogni photosite. Questo particolare sensore è formato da tre elementi fotosensibili a semiconduttore (photodetectors), distribuiti in ogni photosite su tre livelli diversi, ognuno di essi è attivato da una componente R, G o B diversa. Dato che ogni photosite ha tutte e tre le componenti, non c'è necessità di ricavare per ogni photosite le due componenti mancanti perché sono tutte registrate[1].
Algoritmo di demosaicizzazione
L'algoritmo di interpolazione più usato consente la demosaicizzazione dell'immagine originaria calcolando i dati dei due colori mancanti a partire dal colore e intensità dei photosites adiacenti aventi lo stesso colore di quello da calcolare. Ad esempio in un photosite blu si deve calcolare la componente verde e rossa. Per il calcolo della componente mancante verde, il processore d'immagine calcola, per quel photosite, la media fra i valori di intensità del verde di 2 o più photosite adiacenti che hanno registrato il verde: il valore ottenuto sarà la componente verde di quel photosite. Allo stesso modo farà per la componente rossa: il valore ottenuto sarà la componente rossa di quel photosite. A questo punto per quel photosite si hanno a disposizione i dati numerici delle tre componenti RGB, dati che, uniti in una stringa numerica, prendono il nome di pixel e descrivono contemporaneamente cromaticità e luminosità di quel punto dell'immagine.
Il risultato finale è che solo una componente del pixel è letta dal sensore (singolo photodetector), mentre le due rimanenti sono solo stimate.
Nei software applicativi di elaborazione delle immagini digitali, i valori numerici relativi alla componente rossa di ogni pixel dell'immagine, prende il nome di "canale del rosso"; così i valori numerici della componente verde di ogni pixel dell'immagine prendono il nome di "canale del verde" e lo stesso si dice per tutti valori numerici relativi alla componente blu dei pixels che vengono chiamati "canale del blu".
Per una registrazione in JPG il campionamento base è a 8 bit per ognuno dei canali RGB, fatto, questo, che comporta un numero binario di 24 bit per ogni pixel (8 bit x 3 canali su ogni pixel). Il valore di 24 bit rappresenta - come vedremo nel paragrafo successivo - la profondità colore.
Le fotocamere che registrano le immagini in formato JPG operano una compressione delle immagini al fine di:
velocizzare la memorizzazione sul supporto di registrazione;
includere molte immagini sulla stessa scheda di memoria.
La tecnica di compressione JPG è una tecnica di compressione di tipo lossy cioè con perdita di informazione rispetto all'immagine originaria di partenza. L’immagine registrata con questo sistema perde dei dati che corrispondono normalmente a dettagli dell’immagine poco significativi. La quantità e la tipologia dei dati che vengono persi, tuttavia, è determinata in modo tale che essi riguardano parti che normalmente non sono facilmente percettibili da un osservatore. Nella quasi totalità dei casi di foto compresse dalla fotocamera in JPG, la qualità di stampa rimane comunque buona. In generale, adottando uno stesso procedimento di stampa fotografica, la qualità delle stampe è tanto migliore quanto più piccola è la dimensione della stampa. Per stampe professionali di elevata qualità e/o di grandi dimensioni, infatti, si preferisce la gestione dei file grafici in formati non compressi o compressi con tecnica lossless (senza perdita di dati).
Il formato JPG inoltre non consente, fra l'altro, troppe elaborazioni successive delle immagini, a meno di accettare perdite di informazioni che di volta in volta si sommano nei salvataggi successivi. Se una fotocamera registra direttamente in JPG e l'immagine deve subire delle elaborazioni è bene salvarla immediatamente in un formato lossless come può essere il TIFF, il BMP, ecc. e solo quando il processo di elaborazione è terminato si può fare un salvataggio in JPG per l'archiviazione o, se il caso lo richiede, l'eventuale stampa.
Se si adotta la modalità RGB e si campiona a 8 bit il segnale in uscita da ogni photodetector, la profondità colore del file grafico che si andrà a formare sarà di 24 bit, così come se il campionamento è avvenuto a 12 bit, il file grafico avrà una profondità colore di 36 bit. La profondità colore è un indice della capacità che ha il metodo di registrazione dei files di rappresentare sfumature piccolissime di colore. In un’immagine maggiore è la profondità colore, maggiore sarà il numero dei livelli di intensità distinguibili su ognuno dei tre canali RGB e di conseguenza maggiore il dettaglio cromatico dell’immagine. Con una profondità colore di 36 bit ogni pixel infatti è individuato da un solo valore cromatico su 68.719.476.736 parti in cui viene suddiviso l'intervallo spettrale della luce visibile (dal rosso cupo al violetto) catturato dal sensore.
RAW
Come detto sopra, ciò che si registra nel formato RAW sono i segnali digitali a 10, 12, 14 o 16 bit relativi ad ogni pixel del sensore provenienti dalla conversione da analogico a digitale del segnale di ogni photodetector. La registrazione in formato RAW può avvenire senza alcuna compressione, o con una compressione lossless del file del formato RAW, ovvero senza perdita di dati relativi a dettagli di immagine. Tale caratteristica riduce sensibilmente, ma molto meno del JPG, la dimensione del file da registrare. Ogni dettaglio dell’immagine catturata dal sensore viene così registrato e ricostruito senza nessuna perdita in fase di decompressione, esattamente come fanno i programmi di compressione dati che lavorano con i formati ZIP, RAR, ecc. dove nessun dato deve essere perso, pena l’impossibilità di usare i dati decompressi. La registrazione dei dati in uscita dal sensore senza perdita di informazioni e con una elevata profondità colore (dettaglio cromatico), fra l’altro, permette di elaborare l’immagine con un campo di variazione delle regolazioni (esposizione, bilanciamento del bianco, contrasto, ecc) molto maggiore rispetto alla registrazione con altri formati compressi anche di tipo “lossless”. Dunque con una maggiore profondità colore si ha una maggiore potenzialità di elaborazione delle immagini e quindi si sfruttano al massimo le capacità del sensore e dell'ottica.
RAW+JPG
La scrittura e lettura dei file in formato RAW è decisamente più lenta rispetto a quella in formato JPG a causa della maggiore quantità di dati da muovere (in lettura o in scrittura). Questo rende più difficoltosa l'archiviazione dei file e la loro successiva visione. Per facilitare gli utilizzatori, alcuni produttori di fotocamere digitali hanno inserito il doppio formato di registrazione negli apparecchi. Questo consente di leggere l'immagine registrata in formato JPG con una buona velocità (ad es. nelle operazioni di selezione ed archiviazione delle immagini). Mentre è sempre possibile poter utilizzare il formato RAW in caso di bisogno, ad esempio, per la correzione della esposizione. Lo sfruttamento di questa possibilità, com'è ovvio, richiede il trasferimento di una maggiore quantità di dati sui supporti di memoria (con il conseguente allungamento del tempo di memorizzazione), inoltre comporta l'occupazione di uno spazio maggiore di memoria. Ma tale limite non rappresenta un grosso problema visto il continuo incremento di velocità di scrittura delle schede di memoria, ed il loro costo specifico in €/MB che progressivamente diminuisce.
Modalità della doppia registrazione RAW+JPG
Vi sono almeno due modalità con la quale si realizza la doppia registrazione di RAW + JPG.
La prima modalità è quella che prevede la registrazione nella scheda di memoria di 2 files con lo stesso nome, ma con estensione diversa (quella specifica del RAW e JPG). La dimensione e la qualità del file JPG inoltre possono essere anche non elevate, dovendo servire primariamente alla visualizzazione attraverso il monitor in fase di archiviazione (procedura adottata per es. da Konika-Minolta nel modello Dynax 7D). Tuttavia alcune fotocamere consentono di impostare anche la qualità del file JPG registrato insieme al file RAW. In questo modo un qualunque programma di visualizzazione può archiviare, visualizzare ed anche talvolta elaborare i files così registrati in JPG. Per la visualizzazione e l'elaborazione dei formati RAW occorrono invece programmi dedicati/proprietari, oppure servono dei plug-in specifici nei programmi più diffusi per il fotoritocco.
La seconda modalità invece è quella che prevede l'inserimento nello stesso file in formato RAW di due aggregati di dati grafici: quello relativo al formato RAW dell'immagine ripresa e quello con la stessa immagine in formato JPG di qualità e dimensioni ridotte. Questi due insiemi di dati di immagine vengono registrati quindi in un unico file con estensione RAW proprietaria (che per esempio è .RAF per la Fuji). Ma qui per sfruttare i vantaggi della doppia registrazione - vantaggi che consistono sostanzialmente in una maggiore velocità di visualizzazione delle anteprime dei files in fase di achiviazione - occorre normalmente installare sul PC un software di conversione (ad esempio da RAW a TIFF) proprietario della fotocamera. Questo programma durante la sua installazione inserisce (plug-in) nel sistema PC anche un software (con funzione di decoder) per la visualizzazione delle anteprime in JPG presenti dentro ad ogni file RAW. Questo decoder permette al Gestore Risorse del PC il riconoscimento della piccola porzione dei dati JPG dell'immagine inclusa nel file RAW che viene usata come anteprima. A solo titolo di esempio - per un'immagine completa di 3.488 x 2.616 pixel proveniente da un sensore da 9,1 Mpx - l'immagine JPG dentro ad alcuni files .RAF della FUJI ha una dimensione di 1600x1200 pixel registrati in qualità normale, per un ingombro medio di circa 600kB - 800kB, sui complessivi circa 18,7 MB dell'intero file .RAF all'interno del quale sono contenuti questi dati JPG.
Con questi files si può inoltre procedere all'estrazione del file-anteprima JPG integrato nel file RAW, registrando quindi un file JPG separato (operazione realizzabile spesso usando lo stesso software proprietario di conversione). Se non si estrae il file JPG dal file RAW e non lo si scrive come file separato i programmi di gestione delle risorse dei PC continueranno ad individuare un solo file che è quello in formato RAW uscito dalla fotocamera, benché la visualizzazione dell'anteprima avvenga rapidamente con l'estrazione da dentro il file RAW della componente JPG.
Per elaborare un file RAW occorre un software adeguato che possa almeno compiere le operazioni che normalmente compie il processore d’immagine della fotocamera e cioè:
acquisire il file;
applicare l’algoritmo di demosaicizzazione per calcolare le due componenti RGB per ogni pixel non direttamente lette dai singoli elementi unitari fotosensibili del sensore;
formare il file grafico con i tre canali RGB campionati a 8, 10, 12, 14 o 16 bit come previsto dall’hardware della fotocamera (convertitore A/D);
apportare modifiche alle caratteristiche principali dell’immagine (bilanciamento del bianco, esposizione, contrasto, regolazione selettiva dei colori, correzione della gamma dinamica;
convertire e salvare il file RAW in vari formati: non compresso (BMP, TIFF a 8 bit/canale, TIFF a 16 bit/canale, GIF, ecc); oppure compresso con metodi di tipo “lossy” (JPG, JP2, ecc); oppure ancora compresso di tipo “lossless” (TIFF compresso LZW, PNG, ecc) in modo che il file sia leggibile dai normali software di trattamento delle immagini.
Talvolta però questi software fanno molto di più e cioè:
apportano altre modifiche all’immagine, come la correzione della aberrazione cromatica e delle aberrazioni sferiche dovute alla geometria dell’ottica;
rimuovono l’effetto di vignettatura (vignetting) dell’immagine;
riducono il rumore elettronico nelle immagini riprese con scarsa illuminazione;
applicano filtri per il miglioramento del dettaglio dell’immagine e migliorano la nitidezza apparente;
eliminano le interferenze che si generano in alcuni sensori in certe condizioni di ripresa (ad es. l’effetto Moiré)
ecc.
Negli utilizzi professionali o scientifici delle immagini fotografiche può essere mantenuta la profondità colore di 16 bit/canale che porterà ad avere delle immagini con un elevatissimo dettaglio cromatico presentando una profondità colore complessiva sui tre canali RGB di 48 bit. Il formato RAW è usato quindi prevalentemente nella fotografia professionale ed amatoriale di alto livello poiché offre prestazioni ottime, ma a discapito della versatilità infatti:
i files registrati hanno una dimensione notevolmente maggiore del JPEG. La dimensione dei files che si producono in RAW in una fotocamera da 9 MPixel con campionamento a 16 bit è intorno a 18,5 MB contro i 2 MB di un file registrato in JPEG-modalità fine. Questo costringe ad avere supporti di memoria molto capienti;
è opportuno (e a volte necessario) utilizzare un software fornito in dotazione alla fotocamera poiché ogni marca utilizza un formato di codifica RAW che non sempre offre compatibilità trasversale.
Formati proprietari RAW
Nikon: NEF (Nikon Electronic Format);
Kodak: DCR (Digital Camera Raw);
Canon: CRW (Canon RaW, estensione file: *.CR2);
Olympus: ORF (Olympus Raw Format);
Fuji: RAF (RAw Fuji);
Minolta: MRW (Minolta RaW);
Epson: ERW (Epson RaW);
Foveon: X3F.
Pentax: PEF.
Sony: ARW.
Software che supportano i formati RAW
Sono disponibili software di tipo freeware per macchine Fuji come S7RAW per i file di formato RAF. Inoltre esistono software sempre freeware o open source per convertire il RAW:
FastStone Image Viewer (Win)
PhaseOne CaptureOne (30 day trial)
Bibble (Win-Linux) e MacBibble (Mac)
QImage
Camera Raw 2.3 (in Photoshop CS e Elements per Mac e Win)
Extensis Portfolio 6.1.2 (Mac)
iView Media Pro 2.0.3 (Mac e Win)
Graphic Converter 5.1 (Mac)
dcRAW-X 1.5.3 (Mac)
dcraw (Linux - open source)
UFRaw (Linux - open source)
Raw Therapee (Win e Linux)
digiKam (con libRaw - open source)
Mentre a pagamento ci sono
Adobe Camera RAW (Plug-in di Photoshop e Elements per Mac e Win)
Apple Aperture 2 (Mac)
Apple iPhoto '08 (Mac)
Adobe Lightroom (Mac e Win)
ACD See Pro
Per alcuni software di elaborazione delle immagini, è sufficiente scaricare dei plug-in specifici al fine di consentire al programma di leggere il file RAW e salvarlo in un formato che garantisca l'interscambio delle immagini. La caratteristica da considerare adeguatamente quando si usano software non proprietari per elaborare immagini registrate in RAW riguarda la possibilità che questi non riescano ad utilizzare tutti i codici descrittori del file che gli garantiscono tutte le potenzialità d'uso,nonché i codici descrittori dell'impostazione della ripresa dell'immagine (metadati Exif) fra i quali ad esempio quelli relativi ai settaggi delle singole macchine. E questa perdita di metadati può comportare la perdita di flessibilità nella gestione dell'immagine.
Analogie RAW-negativo pellicola e probabile certificazione del copyright
Il formato RAW può essere paragonato, per molti versi, al negativo delle macchine a pellicola. Infatti così come da un negativo su pellicola possono essere realizzate diverse soluzioni cromatiche dell'immagine senza alterare il negativo stesso, anche da un file RAW si possono ottenere, tramite tecniche di post-produzione digitale, molteplici "versioni" dell'originale senza alterare minimamente l'originale in RAW. Inoltre l'immagine grezza rilevata dal sensore e memorizzata in RAW senza nessuna elaborazione, è composta sia dai pixel immagine, caratterizzati dai difetti intrinseci del sensore, sia dal rumore elettronico prodotto dall'attività elettronica dell'apparato. Ciò significa che la stessa immagine ripresa da macchine anche della stessa marca e stesso modello, ma con sensori necessariamente diversi e memorizzate in formato RAW, saranno, ad una analisi in dettaglio dei pixel, diverse una dall'altra così come lo sono i negativi della stessa immagine ripresa con la stessa macchina, ma con pellicole diverse sia pur con le stesse caratteristiche chimiche. Questa peculiarità della memorizzazione in RAW potrà forse consentire la certificazione del copyright anche per immagini digitali a patto di poter dimostrare di possederne gli originali RAW così come il copyright delle immagini su pellicola presuppone il possesso dei negativi originali.
Tuttavia, poiché l'immagine di un file RAW può subire anche elaborazioni molto radicali, come la riduzione calibrata del rumore elettronico (primariamente di origine termica che si genera quasi totalmente nel sensore stesso), o l'eliminazione in essa dei difetti specifici dei sensori come possono essere gli hot pixels; e ancora salvataggi successivi in un formato compresso di tipo lossy come il JPG o interpolazioni per ridimensionare le immagini che portano ad una perdita irrimediabile dei dettagli, si pone un serio problema di metodo per l'analisi comparativa dei dati. Affinché tale analisi possa avere valore in un procedimento legale, occorre perlomeno che le procedure con cui effettuare una possibile perizia - procedure da definire in un ambito di informatica forense - siano prima codificate e poi accettate in ambito giudiziario, stabilendo fra l'altro un criterio per accettare la comparazione fra supporti diversi, oltre che limiti statistici di corrispondenza fra pixel o gruppi di pixel o aree delle immagini comparate.
Le scheda di memoria di tipo CompactFlash hanno un formato di 42,8 X 36,4 mm con uno spessore che cambia a seconda del tipo; esistono infatti due tipi di questo modello:
CompactFlash Tipo I con uno spessore di 3,3 mm
CompactFlash Tipo II con uno spessore di 5 mm
La capacità delle schede CompactFlash varia attualmente da 16 MB a 64 GB a seconda del modello, anche se le attuali specifiche permettono di raggiungere teoricamente i 137 GB.
Con lo standard CF+, revisione 2.0, la velocità di trasferimento è stata aumentata a 16 MB/s (sulla scheda la velocità è indicata usando un fattore di moltiplicazione: ad esempio, "40x" equivale ad una velocità di 6 MB/s).
Nel corso del 2005 sono state introdotte delle nuove specifiche tecniche (CF 3.0) che, tra l'altro, supportano una velocità di trasferimento di 66 MB/s. Lo standard CF 4.0 supporta IDE Ultra DMA 133, che permette di raggiungere una velocità di trasferimento massima di 133 MB/s.
Nate inizialmente per le fotocamere digitali, visto il grande successo si sono diffuse anche in altri campi, come ad esempio nell'audio digitale.
La CompactFlash Association ha annunciato a luglio 2007 lo sviluppo di un'interfaccia SATA per le CompactFlash. [1]
Il Memory Stick è uno standard di scheda di memoria creato dalla Sony, introdotto nel 1999 e presto giunto a coprire circa un quarto del mercato delle memory card. In realtà, il termine Memory Stick include una molteplicità di dispositivi diversi evolutisi nel tempo. La prima Memory Stick aveva dimensioni limitate a 128 MB ed esiste in versione "regular" e "OpenMG" (Magic Gate), di cui solo l'ultima in grado di gestire file audio. Nei telefoni cellulari è attualmente usata una versione di dimensioni più ridotte (è poco più piccola di una Secure Digital), la Memory Stick Duo.
Esiste poi la Memory Stick PRO, sviluppata in collaborazione da Sony e Sandisk, caratterizzata da capacità e velocità piu elevate. Abbinata a dispositivi adeguati, questo tipo di Memory Stick rende possibile registrare audio e video in tempo reale ad alta risoluzione.
// if (window.showTocToggle) { var tocShowText = "mostra"; var tocHideText = "nascondi"; showTocToggle(); } // Caratteristiche
Dimensioni:
Memory Stick (standard e PRO): 50 × 20 × 2,5 mm;
Memory Stick Duo: 30 × 20 × 1,5 mm.
 Capacità massima:
Capacità massima:
standard, Duo: 128 MB;
PRO: 2 GB;
PRO Duo: 8 GB;[1]
PRO Duo (Mark2): 16 GB.
Da SanDisk nel gennaio 2007 vengono presentate le nuove memorie Memory Stick M2 in tagli da 512 MB, 1 GB, 2 GB e 4 GB.
Nel febbraio 2007 Sony mette in vendita dal suo sito le Memory Stick Pro Duo da 8 GB.
Da marzo 2008 è disponibile la versione da 16 GB della nuova Memory Stick PRO Duo (Mark2).
Nel 2007 Sony e SanDisk commercializzano le nuove memorie Memory Stick Pro HG-Duo, caratterizzate da una interfaccia parallela ad 8 bit con una velocità massima di trasferimento dati di 60 MB/secondo e capacità di scrittura a 15 MB/s. Avranno una capienza fino a 32 GB.
La MultiMediaCard (MMC) è stato uno dei primi standard di memory card a comparire sul mercato, insieme alle SmartMedia. È meno soggetta agli urti perché più robusta. Ha la stessa forma e la stessa piedinatura delle successive Secure Digital (SD), con le quali è compatibile: una MMC entra in uno slot per una SD, ma non è vero il contrario, perché le SD sono più spesse. Alcuni lettori MP3 non supportano le MMC perché queste, a differenza delle SD, non supportano i contenuti criptati. Inoltre le MMC, a differenza delle SD, non hanno lo switch che permette di proteggerle dalla scrittura.
 RS MMC con adattatore
RS MMC con adattatore
Esiste anche una versione di MMC di dimensioni ridotte, chiamata RS-MMC (Reduced Size MultiMedia Card), del tutto identica nelle specifiche alla MMC classica, tranne che per le dimensioni, ridotte di circa la metà. Questo tipo di memory card è stato introdotto nel 2004. Attraverso un adattatore che serve semplicemente ad estendere le dimensioni della card le RS-MMC possono essere usate in qualsiasi slot per MMC (o SD). Attualmente sono disponibili in vari formati che possono arrivare fino a un massimo di 8 GB. Questo tipo di card è molto usato dalla Nokia nei suoi smartphone della Serie 60 e dalla Siemens.
DV RS MMC o MMCmobile
 Le nuove carte RS-MMC, usate nei cellulari Nokia più recenti (come il Nokia 6630, il 6680 e l'N70), utilizzano un voltaggio più basso (1.8 V invece di 3 V) per ridurre il consumo della batteria. Queste card RS MMC a basso voltaggio sono conosciute come Dual-Voltage Reduced-Size MMC (DV RS-MMC), e possono essere messe in commercio come MMCmobile quando soddisfano gli standard per le cards MMCmobile. Questi dispositivi di memoria sono compatibili con le vecchie RS-MMC.
Le nuove carte RS-MMC, usate nei cellulari Nokia più recenti (come il Nokia 6630, il 6680 e l'N70), utilizzano un voltaggio più basso (1.8 V invece di 3 V) per ridurre il consumo della batteria. Queste card RS MMC a basso voltaggio sono conosciute come Dual-Voltage Reduced-Size MMC (DV RS-MMC), e possono essere messe in commercio come MMCmobile quando soddisfano gli standard per le cards MMCmobile. Questi dispositivi di memoria sono compatibili con le vecchie RS-MMC.
MMC mobile
In alcuni cellulari sono state utilizzate, viste le ridotte dimensioni, le schede MMC micro, che con un apposito adattatore possono essere lette nei lettori di MMC. Sono poco diffuse come tipologie di schede, essendo utilizzate solo su alcuni modelli di cellulari Samsung come il d730. La scheda appare molto simile alla MicroSD ma risulta essere tuttavia incompatibile per pin e dimensioni fisiche. Anche la MMC micro sfrutta la tecnologia dual voltage
Caratteristiche
dimensioni: 30 x 23 x 1,4 mm (RS-MMC: 18 x 24 x 1,4 mm) (MMC mbile: 14mm x 11mm x 1.1mm)
velocità trasferimento dati: fino a 2,5 MB/sec
resistenza alle vibrazioni: 15 g
resistenza agli urti: 1000 g
consumo di corrente: max 60 mA
alimentazione: 2,7 - 3,6 V
Secure Digital
 (chiamate più brevemente SD) è il più diffuso formato di schede di memoria, dispositivi elettronici utilizzati per memorizzare in formato digitale grandi quantità di informazioni all'interno di memorie flash (vedi anche SDIO).
(chiamate più brevemente SD) è il più diffuso formato di schede di memoria, dispositivi elettronici utilizzati per memorizzare in formato digitale grandi quantità di informazioni all'interno di memorie flash (vedi anche SDIO).
 Le "Secure Digital" hanno capacità molto elevate, seconde solo alle CompactFlash; attualmente raggiungono una capacità di 32 GB. Molti Notebook sono già equipaggiati con lettori appositi che consentono l'utilizzo di queste schede di memoria. Pur essendo le SD di dimensioni alquanto ridotte (32 x 24 x 2,1 mm), è già stata introdotta una nuova versione chiamata mini-SD (21,5 x 20 x 1,4 mm); esiste poi un altro tipo, chiamato inizialmente T-Flash, poi transflash e infine stabilizzatosi in microSD una volta adottato dalla SD Card Association, compatibile con le SD e di dimensioni ancora più contenute (11 x 15 x 1 mm). Sia le microSD che le miniSD possono essere utilizzate con lettori di SD mediante semplici adattatori.
Le "Secure Digital" hanno capacità molto elevate, seconde solo alle CompactFlash; attualmente raggiungono una capacità di 32 GB. Molti Notebook sono già equipaggiati con lettori appositi che consentono l'utilizzo di queste schede di memoria. Pur essendo le SD di dimensioni alquanto ridotte (32 x 24 x 2,1 mm), è già stata introdotta una nuova versione chiamata mini-SD (21,5 x 20 x 1,4 mm); esiste poi un altro tipo, chiamato inizialmente T-Flash, poi transflash e infine stabilizzatosi in microSD una volta adottato dalla SD Card Association, compatibile con le SD e di dimensioni ancora più contenute (11 x 15 x 1 mm). Sia le microSD che le miniSD possono essere utilizzate con lettori di SD mediante semplici adattatori.
Le SD sono molto resistenti agli urti (2000 g, contro i 100-200 g di un comune hard disk). Analogamente alle MultiMediaCard, le SD utilizzano contatti superficiali anziché connettori maschio-femmina, fatto che ne aumenta ulteriormente la robustezza.
La capacità massima attuale delle SD è di 32 GB (16 GB prima di gennaio 2008); per le miniSD il limite è di 4 GB e per le microSD di 16 GB[1]
Esiste anche un particolare tipo di SecureDigital che incorpora un connettore USB, e permette di collegare la SD a un computer senza bisogno di appositi lettori.[2]
Un'altra evoluzione delle SD sono le SDIO, che incorporano meccanismi di gestione dell'Input/Output che permettono di realizzare dispositivi particolari (fotocamere digitali, registratori vocali e altro) collegabili a dispositivi elettronici dotati di slot SDIO. (v. ad es. [1])
Nel 2006 Philips al Computex di Taipei ha presentato una scheda SD con ricevitore televisivo integrato con tecnologia DVB-H. Verrà messo sul mercato nell'estate dello stesso anno anche con un'antenna.
SDHC
Le SD superiori ai 2 GB e con una velocità minima di lettura/scrittura di 2,2 MB/s vengono nominate col nuovo termine: SDHC (Secure Digital High Capacity, Secure Digital ad alta capacità) che non sono compatibili con i vecchi lettori di schede SD. Sono anche chiamate SD 2.0. Le SDHC sono classificate in base alla velocità di scrittura, che le divide in classi. La capacità massima teorica dello standard SDHC è di 32 GB.
Le SDHC hanno anche una indicazione della velocità di trasferimento detta SD Speed Class Ratings definita dalla SD Association. La classe di velocità indica la velocità minima di scrittura continua su una scheda SDHC vuota espressa in MB/s, la classi definite sono:
Classe 2: 2 MB/s
Classe 4: 4 MB/s
Classe 6: 6 MB/s
A marzo del 2007 SanDisk ha presentato al PMA di Las Vegas una SDHC da 8 GB. [3] Nell'agosto del 2007 Toshiba presenta la prima SDHC da 32 GB.[4] (È disponibile commercialmente da gennaio 2008)
Nel novembre 2007 Transcend annuncia schedine SDHC Classe 6 da 16 GB come A-Data nel settembre 2007. L'uscita commerciale e prevista per la fine del 2007.[5]
Compatibilità tra SD e SDHC
All'inizio del 2007 sono comparse sul mercato SD non standard di capacità di 4 GB, che possono non essere lette da tutti i lettori SD, specialmente da quelli meno recenti. Per chiarezza sulla compatibilità si può dire:
I dispositivi che non dichiarano il supporto SDHC non sono in grado di riconoscere le schede SDHC
Schede di 4 GB non marcate come SDHC, non sono conformi né allo standard SD né a quello nuovo SD2.0/SDHC
SDXC
Le SD con capacità superiori ai 32 GB verranno chiamate col il nuovo termine: SDXC (Secure Digital eXtended Capacity, Secure Digital a capacità estesa). La capacità massima teorica dello standard SDXC è di 2048 GB (2 TB).[6]
La SmartMedia (SM) è uno dei tanti tipi di Memoria flash esistenti, piccoli supporti elettronici in grado di archiviare grandi quantità di dati in formato digitale.
In un primo momento il suo nome avrebbe dovuto essere Solid State Floppy Disk Card (SSFDC): la scheda era pensata come successore dei floppy disk (benché sia negli anni novanta che negli anni 2000 il maggior utilizzo delle schede di memoria si sia rivelato invece all'interno di periferiche portatili) e ne ricordava la forma.
Fra i primi tipi di scheda di memoria a comparire sul mercato, nel 1995, le card di questo tipo sono molto sottili, spesse all'incirca quanto una carta da gioco. Questo le rende particolarmente flessibili e quindi piuttosto fragili. La SmartMedia non è dotata di un controller interno che permetta al sistema operativo di considerarla alla stregua di un qualunque drive rimovibile, ed alcuni dispositivi non sono in grado di gestire SmartMedia con capacità superiori ai 16 o 32 MB, anche se il limite architetturale effettivo di queste card è di 128 MB. La mancanza del controller permetteva costi di produzione contenuti.
Utilizzate per lo più da Fuji e Olympus nelle macchine fotografiche digitali, sono state rimpiazzate dalle due case costruttrici dal nuovo formato xD-Picture Card.
Le dimensioni della SmartMedia sono 45,72 x 38,1 x 1,5 mm.
La piedinatura (pinout) della SmartMedia è illustrata in questa pagina (in inglese): http://pinouts.ru/data/smatrmedia_pinout.shtml
Le piedinature di altre memory card e altri dispositivi elettronici in generale sono disponibili sullo stesso sito: http://pinouts.ru
La xD-Picture Card è un tipo di scheda di memoria flash ideata da Fujifilm e Olympus, produttori di macchine fotografiche e fu immessa sul mercato nel luglio 2002. Il nome xD deriva dall'acronimo extreme Digital. Le schede xD vengono prodotte dalla Toshiba Corporation e dalla Samsung Electronics per conto di Olympus e Fujifilm anche se ne esistono di diverse marche tra cui SanDisk, Lexar e Kodak.
Le schede xD trovano largo impiego nelle fotocamere digitali Fujifilm e Olympus e nella serie di registratori digitali prodotti sempre dalla Olympus. Fujifilm invece ha prodotto un lettore mp3 che si serve di questo supporto. Sono disponibili nei seguenti tagli 16, 32, 64, 128, 256, 512, 1024, 2048 MiB ed hanno dimensioni (fisiche) di 20 x 25 x 1.78 millimetri per un peso di 2.8 grammi.
xD Type M e Type H
Le prime xD disponibili sul mercato avevano capacità comprese tra i 16 ed i 32 MB. Le xD Type M invece, prodotte dal Febbraio 2005, utilizzano l'architettura MLC (MultiLevel Cell) per raggiungere capacità teoriche di 8 GB. Al luglio 2007 la capacità massima di una xD Type M è di 2 GB. Sebbene le Type M offrano una maggiore capacità di memorizzazione, esse sono più lente in lettura e scrittura rispetto alla versione originale. Le xD Type H, prodotte a partire dal Novembre 2005 offrono capacità di memorizzazione pari a quelle delle Type M ad una velocità in lettura e scrittura più elevata (teoricamente 3 volte maggiore).
Secondo Olympus oltre alla velocità maggiore le xD Type H supportano effetti speciali aggiuntivi sulle immagini quando utilizzate in alcuni modelli di fotocamere Olympus. Comunque queste caratteristiche sono semplicemente dipendenti dal software della fotocamera poiché non dipendono dall'hardware utilizzato per la costruzione della memoria. Data però la maggiore velocità di trasferimento dati, l'utilizzo di xD Type H è obbligatorio nel caso ad esempio di cattura video ad alta qualità (640 x 480 x 30 fps).
Retrocompatibilità
A causa del cambio di architettura di memorizzazione, le Type M e Type H potrebbero risultare incompatibili con modelli più obsoleti di fotocamere digitali. Le schede più nuove sono anche incompatibili con alcuni lettori di memory card. Inoltre se non si pone attenzione durante l'inserimento della scheda nel lettore, si cortocircuita la scheda rendendola inutilizzabile con la conseguenza di perdere i dati, e quindi da buttare. È preferibile collegare la scheda al computer tramite la fotocamera e cavo USB. Anche utilizzando questo modo, in alcuni casi si verificano ancora perdite di dati, ma la scheda continua a funzionare.
Di seguito sono disponibili le risposte ad alcune domande comuni sui tipi di file di immagine.
Che cos'è un tipo di file?
Un tipo di file rappresenta un metodo standard di archiviazione delle informazioni in un computer in modo che queste possano essere lette o visualizzate tramite un programma. Un tipo di file è in genere riconoscibile dalle ultime tre lettere del nome di file. Tali lettere vengono definite come estensione di file. Per il salvataggio, in ogni programma viene utilizzata un'estensione di file specifica.
Quali sono i tipi di file più comuni per le immagini?
Tra i tipi di file di grafica più comuni vi sono i formati JPEG, TIFF e bitmap (rispettivamente con estensione jpg, tif e bmp). In alcune fotocamere digitali è inoltre possibile salvare le immagini in formato RAW, un tipo di file non compresso al quale non vengono applicati effetti quali il bilanciamento del bianco o l'aumento della nitidezza.
Quale tipo di file è consigliabile utilizzare?
Nella maggior parte dei casi, il formato JPEG (con estensione jpg) rappresenta la scelta più indicata, poiché consente di creare immagini di qualità elevata con dimensioni di file ridotte grazie alla compressione dei dati. Questo è il formato ottimale per l'archiviazione e la condivisione delle immagini. Se è necessario un livello di qualità visiva molto elevato (ad esempio se si stampano ingrandimenti da 8 x 10 pollici), è consigliabile salvare l'immagine in formato TIFF (con estensione tif) oppure salvare l'immagine JPEG con il minimo livello di compressione disponibile.
Quali sono i vantaggi e gli svantaggi dei tipi di file di immagine più comuni?
Formato JPG |
Formato TIFF |
||
Vantaggi |
Svantaggi |
Vantaggi |
Svantaggi |
|
Poiché nel formato JPEG le immagini vengono compresse automaticamente al momento del salvataggio, si verifica una leggera riduzione della qualità visiva. |
Nelle immagini salvate in formato TIFF non si verifica alcuna perdita di qualità. |
In alcuni programmi, tra cui la maggior parte dei Web browser, non è possibile visualizzare le immagini in formato TIFF. |
Le immagini in formato JPEG sono ideali per l'invio tramite posta elettronica, grazie alle dimensioni ridotte. |
Se si utilizza un livello di compressione elevato, è possibile che la qualità dell'immagine risulti scarsa. |
|
Le immagini TIFF possono raggiungere dimensioni molto elevate (una stessa immagine salvata in formato JPEG ha dimensioni notevolmente inferiori). Di conseguenza, le immagini TIFF riducono lo spazio su disco molto più rapidamente rispetto alle immagini JPEG. |
Poiché è possibile variare il livello di compressione utilizzato per il salvataggio di un'immagine JPEG, è possibile controllare le dimensioni del file e la qualità dell'immagine. |
|
|
Ad eccezione di quelle di dimensioni molto ridotte, le immagini TIFF sono troppo grandi per essere inviate tramite posta elettronica. |
È possibile utilizzare i formati GIF, bitmap, PNG, RAW e altri tipi di file?
Non è quasi mai necessario utilizzare tipi di file diversi dai formati JPEG e TIFF. Il formato bitmap (con estensione bmp) è uno standard di tipo precedente che crea file di dimensioni inutilmente eccessive. Queste immagini occupano molto spazio su disco ed è complesso inviarle tramite posta elettronica. I formati GIF e PNG vengono comunemente utilizzati nelle pagine Web, ma a questo scopo è possibile utilizzare anche il formato JPEG. Il formato RAW viene invece utilizzato in molte fotocamere digitali come alternativa di elevata qualità al formato JPEG. Molti fotografi professionisti preferiscono utilizz are file RAW per ottenere la miglior qualità di immagine possibile.
È possibile utilizzare le immagini RAW in Windows?
Non per il momento. È possibile che un software per la visualizzazione delle immagini RAW venga reso disponibile come aggiornamento a Windows. A ogni avvio di Raccolta foto, Windows verifica l'eventuale disponibilità di tali aggiornamenti. Nel caso siano disponibili, sarà possibile installarli. Dopo l'installazione del software appropriato, sarà possibile aprire e visualizzare tramite Raccolta foto alcuni tipi di immagini RAW. Se si modifica un'immagine RAW, la versione modificata verrà salvata come JPEG e l'immagine originale rimarrà invariata.
Perché nel nome di file delle immagini RAW non è inclusa l'estensione raw?
Sebbene ogni produttore di fotocamere digitali utilizzi un tipo di file specifico per l'impostazione di massima qualità, tutti questi file vengono definiti di tipo RAW. Ad esempio, i nomi di file RAW nelle fotocamere Nikon terminano con estensione nef, mentre nelle fotocamere Canon vengono utilizzate le estensioni crw e cr2, a seconda del modello. Tutti questi diversi file vengono tuttavia definiti come file RAW.
Quanto è elevata la perdita di qualità visiva quando si salva un'immagine in formato JPEG?
![]() Le immagini JPEG sono una copia imperfetta dell'immagine originale visualizzata nel mirino della fotocamera. Se tuttavia si imposta il massimo livello di qualità della fotocamera, la corrispondenza con tale immagine può essere quasi perfetta. A ogni successivo salvataggio di un'immagine in formato JPEG, la qualità visiva si riduce leggermente, come quando si esegue la fotocopia di una fotocopia. La perdita di qualità è proporzionale al livello di compressione dell'immagine. In genere, questa riduzione è difficile da percepire. Se tuttavia si apportano ripetute modifiche alla stessa immagine salvandola con un livello di qualità intermedio, è possibile che si noti una perdita di nitidezza e di resa dei colori. Per ottenere la miglior qualità visiva possibile, salvare le immagini JPEG con il massimo livello di qualità oppure utilizzare il formato TIFF.
Le immagini JPEG sono una copia imperfetta dell'immagine originale visualizzata nel mirino della fotocamera. Se tuttavia si imposta il massimo livello di qualità della fotocamera, la corrispondenza con tale immagine può essere quasi perfetta. A ogni successivo salvataggio di un'immagine in formato JPEG, la qualità visiva si riduce leggermente, come quando si esegue la fotocopia di una fotocopia. La perdita di qualità è proporzionale al livello di compressione dell'immagine. In genere, questa riduzione è difficile da percepire. Se tuttavia si apportano ripetute modifiche alla stessa immagine salvandola con un livello di qualità intermedio, è possibile che si noti una perdita di nitidezza e di resa dei colori. Per ottenere la miglior qualità visiva possibile, salvare le immagini JPEG con il massimo livello di qualità oppure utilizzare il formato TIFF.
FORMATI SALVATAGGIO E COMPRESSIONE
PER IMMAGINI/FOTO
 E' risaputo che le immagini occupano tanto spazio sul nostro disco fisso in quanto l'immagine complessiva è data dalla somma di tanti puntini, o pixel, ognuno dei quali deve essere "ricordato" dal computer, e quindi occupa memoria. A seconda quindi dell'uso che si deve fare delle foto/immagini, che sia per creare uno slideshow, inserire delle immagini sul web, aggiungere fotografie digitali durante il video editing o per la stampa, è necessario scegliere il formato di salvataggio e di compressione corretto. Quando l'immagine è salvata su disco, è possibile usare un formato che comprima le informazioni, di modo che le dimensioni del file su disco risultino inferiori cercando di non perdere troppo in qualità. Le tecniche di compressione sono suddivise in base alla perdita di colore e di dettagli dell'immagine. Le tecniche "senza perdite", comprimono i dati delle immagini senza diminuirne il dettaglio od i colori, mentre le tecniche "con perdite" ("lossy"), comprimono i dati delle immagini perdendo dettagli o/e colori.
E' risaputo che le immagini occupano tanto spazio sul nostro disco fisso in quanto l'immagine complessiva è data dalla somma di tanti puntini, o pixel, ognuno dei quali deve essere "ricordato" dal computer, e quindi occupa memoria. A seconda quindi dell'uso che si deve fare delle foto/immagini, che sia per creare uno slideshow, inserire delle immagini sul web, aggiungere fotografie digitali durante il video editing o per la stampa, è necessario scegliere il formato di salvataggio e di compressione corretto. Quando l'immagine è salvata su disco, è possibile usare un formato che comprima le informazioni, di modo che le dimensioni del file su disco risultino inferiori cercando di non perdere troppo in qualità. Le tecniche di compressione sono suddivise in base alla perdita di colore e di dettagli dell'immagine. Le tecniche "senza perdite", comprimono i dati delle immagini senza diminuirne il dettaglio od i colori, mentre le tecniche "con perdite" ("lossy"), comprimono i dati delle immagini perdendo dettagli o/e colori.
Di seguito potrai trovare i formati di salvataggio per le foto divisi in base all'uso che se ne deve fare.
Per pubblicare foto sul web è essenziale che siano "leggere". Infatti la qualità è limitata al video, quindi non serve un'eccessiva risoluzione. Di seguito i formati più adatti e utilizzati.
JPEG
.JPG
Questo formato supporta le gestioni di colore RGB, CMYK e scala di grigio ma non supporta il canale Alpha (il canale della trasparenza). Il JPEG conserva tutte le informazioni del colore di un'immagine RGB e comprime la dimensione del file eliminando dati in modo selettivo, maggiore è questo valore di compressione e minore sarà la qualità finale dell'immagine.
Un'immagine JPEG si decomprime automaticamente all'apertura.
Il formato JPEG utilizza per la compressione un algoritmo cosiddetto lossy, ovvero con perdita di informazione se è utilizzato con la minore percentuale di compressione la risoluzione (il numero di pixel dell’immagine) non comporta una riduzione del numero di pixel quindi di qualità.
Ogni volta che si salva un file .jpg, dopo averlo, ad esempio, corretto o ridimensionato, si ha un uteriore perdita di qualità.
La soluzione? Salvare il file modificato con un altro nome in modo da mantenere il file originale intatto e senza perdita di qualità per eventuali successivi ritocchi.
E’ il formato ideale per lo slideshow - fotoshow o per l’inserimento di immagini in un filmato video con l’utilizzo di un programma di video editing.
GIF
.GIF.
Ideale per la rappresentazione di immagini sul Web come gif animate, pulsanti e intestazioni.
Non è invece adatto alle fotografie a colori, in quanto memorizza solo 256 colori e per immagini che necessitino di alta qualità.
Il GIF (Graphics Interchange Format) è un formato compresso senza perdita di dati. Non supporta il canale Alpha (il canale della trasparenza).
Offre la possibilità di creare animazioni (gif animate).
PNG
(Portable Network Graphics) E' un formato utilizzato per la rappresentazione di immagini sul web. E' l'alternativa al GIF.
E' però possibile che vecchi browser non supportino il formato PNG. Per questa ragione, i webmaster tendono ad evitarne l'uso.
Consente una visualizzazione da 256 a 16,7 milioni di colori, può essere compresso senza generare alcuna perdita di dati e supporta 256 livelli di trasparenza. Col limite di non consentire animazioni.
Quasi tutti i programmi per slideshow - fotoshow leggono molti formati, e col Jpeg si va sempre sul sicuro. L'esigenza è quella di avere una risoluzione adatta alla tv, quindi niente di eccessivo. Dalla propria fotocamera è possibile impostare la risoluzione, di solito quella media (la via di mezzo) è perfetta.
JPEG
E’ il formato ideale per lo slideshow o per l’inserimento di immagini in un filmato video con l’utilizzo di un programma di video editing. Soprattutto perchè è il formato supportato dalla maggior parte delle fotocamere digitali. Tutte le fotocamere digitali supportano il formato JPEG, quelle ultra compatte o di prezzo basso spesso offrono il supporto al solo JPEG (salvo che non si scelga di lavorare nel più professionale e ingombrante formato RAW, che però risulta oggettivamente eccessivo nella maggior parte delle situazioni concrete).
La compressione varia dal 50 al 99% a seconda della qualità del JPEG (Super Fine, Fine, ) che abbiamo impostato sulla fotocamera, quindi è meglio controllare la qualità impostata dal menù della fotocamera per non trovarci con foto di altissima qualità (inutile per il video) e pochissimo spazio sulla scheda di memoria. Per un buono slideshow è sufficiente una risoluzione media con conseguente risparmio di spazio. Più spazio sulla scheda più foto da scattare. Un'immagine JPEG si decomprime automaticamente all'apertura.
Il formato JPEG utilizza per la compressione un algoritmo cosiddetto lossy, ovvero con perdita di informazione se è utilizzato con la minore percentuale di compressione la risoluzione (il numero di pixel dell’immagine) non comporta una riduzione del numero di pixel quindi di qualità.
Ogni volta che si salva un file .jpg, dopo averlo, ad esempio, corretto o ridimensionato, si ha un ulteriore perdita di qualità.
La soluzione? Salvare il file modificato con un altro nome in modo da mantenere il file originale intatto e senza perdita di qualità per eventuali successivi ritocchi.
Le immagini fotografiche digitali possono essere destinate alla stampa. Anche per la stampa è necessario scegliere il formato corretto a seconda che sia ad alta qualità, per stampanti ad uso casalingo o per i libri fotografici online. Per stampare dalla stampante di casa (vedi Guida alla scelta della stampante) le foto della vacanza o della famiglia si può tranquillamente utilizzare il formato JPEG in quanto è quello supportato dalle più diffuse fotocamere digitali e da qualsiasi programma per archiviazione foto. Lo stesso vale se dobbiamo "inviare" le foto ad uno dei siti che offrono servizio di stampa di libri fotografici su Internet. Mentre il formato TIFF si distingue per l'alta qualità e viene quindi utilizzato per stampare ad alti livelli di risoluzione.
TIFF
.TIF
E' il formato principe per la stampa di qualità. Può infatti supportare salvataggi a milioni di colori, il supporto del canale Alpha per la trasparenza ed i vantaggi della compressione LZW "senza perdita".
La grafica è un settore molto esteso che comprende varie categorie. Per tale motivo prendiamo in considerazione il formato per antonomasia dedicato alla grafica e in particolare per l'illustrazione: l'EPS.
EPS
.EPS
E' un formato utilizzabile da tutti i programmi di grafica, di illustrazione e impaginazione sia raster che vettoriali. Questo formato può contenere sia immagini bitmap che vettoriali. L'EPS (Encapsulated PostScript) supporta le gestioni di colore Lab, RGB, CMYK, scala di colore, scala di grigio, due tonalità e Bitmap. Non supporta il canale Alpha (il canale della trasparenza). Supporta i tracciati di ritaglio.
Per formati immagine professionali si intende il formato che meglio si presta alle esigenze di alta qualità richieste da un fotografo professionista e dalla sua macchina fotografica digitale. In tal senso si deve prendere in considerazione il formato RAW.
RAW
Normalmente le immagini vengono salvate dagli utenti "consumer" sulle fotocamere in solo formato Jpeg perche' "pesano" di meno ed è più semplice maneggiarle per il poco spazio occupato e la buona qualità (a bassi interventi di compressione) che si ottiene.
Più pesante del JPEG ma più leggero del TIFF il RAW sta guadagnando consensi, specie tra chi non vuole scendere a compromessi e ottenere così il massimo dalle proprie fotografie scattate in digitale.
Col formato RAW si è in grado di gestire l'immagine come arriva, senza interpolazione e compressione e di apportare tutte le modifiche in un tempo successivo mantenendo tutte le informazioni che sono state catturate dal sensore nel momento dello scatto senza che venga efettuato l'intervento di interpolazione del convertitore interno della macchina fotografica.
Alcune fotocamere digitali di alto livello permettono la registrazione contemporanea dell’immagine sia in formato RAW sia in formato JPEG. Spetterà al software o a diversi software l'interpretazione dei dati e il loro rendering finale per l'uscita su schermo o in stampa.
Se salvate in formato RAW e volete rivedere l'immagine sul computer dovete effettuare la conversione con un software che applica l'interpolazione Bayer secondo algoritmi decisi dallo sviluppatore che puo' essere il produttore della fotocamera stessa o una terza parte come Adobe o Apple.
BMP
BMP sta per Bitmap ed è il formato originale di Windows per le immagini.
Si tratta di un formato non compresso, ma che permette di essere visualizzato, da chi possiede Windows, senza l’uso di programmi particolari.
PCX
Il formato PCX consente di salvare file in formato compresso.
I file PCX si basano sui pixel come nel BMP, ma occupano meno spazio perché si tratta di un formato compresso.
PSD
Formato originale dei documenti Adobe Photoshop. Il formato .psd è usato principalmente come formato di lavoro e come "master" da cui esportare a tutti gli altri formati secondo necessità. I documenti salvati nel formato grafico PSD mantengono informazioni come: livelli, maschere, canali e altro.
Lo svantaggio del formato PSD sono le dimensioni. Il peso del file diventa non indifferente.
Tra le altre informazioni che possono essere salvate troviamo didascalie, titoli, parole chiave ed informazioni sull’autore.
DCS
Sviluppato da Quark, è una versione dell'EPS.
TGA
Sono utilizzati molto per memorizzare immagini prese da video.
PDF
si associa il .PDF ad "Adobe Acrobat", sia nella già citata versione gratuita "reader" ( legge ma non permette di creare o modificare i .PDF) , sia nella COSTOSISSIMA versione a pagamento : un elaborato software che si appoggia ad altri editor esistenti ( ad esempio anche Word o Power Point) per "distillare" il loro elaborato come file .PDF.
PICT
Il .PICT è un formato grafico tipico dei Macintosh.
Per far riconoscere i file PICT su un PC con sistema operativo Windows è necessario rinominare i file cambiando l’estensione in .pct
fonte: http://www.riccardomancini.it/CorsoGrafica/Documentazione/Guida%20alla%20fotografia%20digitale.doc
Autore del testo: non indicato nel documento di origine
Guida alla fotografia digitale
La digitalizzazione delle immagini
Per rendere una informazione comprensibile ad un computer è necessario esprimerla sotto forma di una sequenza di bit ovvero sotto forma di 0 e 1.
Consideriamo il semplice caso di un disegno in bianco e nero come quello che vediamo nella figura che segue:
Per estrarre la sequenza di bit che rappresenti il suddetto disegno possiamo procedere in questo modo:
- per prima cosa dividiamo il disegno in quadratini molto piccoli, chiamati pixel, sovrapponendogli una griglia
- ad ogni quadratino della griglia diamo il colore nero se il contenuto di nero al suo interno supera quello del bianco, e viceversa diamo il colore bianco se il contenuto del bianco al suo interno supera quello del nero.
La successiva figura rappresenta proprio la nuova immagine che otterremo dopo aver portato a termine la suddetta operazione.
A questo punto, ad ogni quadratino o pixel della griglia associamo uno 0 se il suo contenuto è il bianco e 1 in caso contrario.
In tal modo otterremo una lunga sequenza di 0 e 1 che codifica l’immagine della lampadina in formato digitale.
La nostra immagine di partenza, dopo questa operazione si è dunque trasformata in una sorta di mappa composta di 0 e 1, ed infatti il nome tecnico che si usa per descrivere questa sequenza di bit è proprio bitmap.
Ovviamente, più fitta è la griglia che sovrapponiamo all’immagine e più la nostra rappresentazione digitale risulterà fedele all’originale.
D’altra parte, una griglia più fitta significa un maggior numero di pixel e quindi un maggiore numero di bit che dovranno essere utilizzati per descrivere digitalmente l’immagine.
Per un’immagine di partenza viceversa a colori, per ogni quadretto, o meglio per ogni pixel, anziché utilizzare solo uno 0 ed un 1, utilizzeremo una combinazione di 0 e 1 in base a una tabella di codifica dei colori.
La successiva tabella di codifica dei colori è ad esempio composta di 64 colori, e quindi ad ogni pixel potremo assegnare un numero da 0 a 63 in binario che individuerà uno solo dei colori della tabella stessa.
Dato che per esprimere in binario numeri fino a 63 sono necessari sei bit, vorrà allora dire che ad ogni pixel dell’immagine corrisponderà una combinazione di sei bit.
Ovviamente serviranno tanti più bit quanti più colori utilizziamo.
Se infatti usiamo 8 bit per ogni pixel, i colori che possiamo utilizzare nella nostra immagine saranno 256.
Se invece usiamo 16 bit per ogni pixel, i colori che possiamo utilizzare nella nostra immagine saranno 65536, e così via.
La maggior parte delle schede grafiche utilizza ormai 24 bit per ogni pixel o addirittura 32 bit per ogni pixel.
Le immagini codificate pixel per pixel con il procedimento appena visto, danno corpo, come si è già accennato, ai cosiddettti file bitmap, ed appunto caratterizzati dall’estensione .BMP
I dispositivi fisici per digitalizzare le immagini sono: lo scanner e la fotocamera digitale.
Vista come avviene la trasformazione di una immagine in bit, possiamo adesso esaminare quali sono e come funzionano i principali dispositivi fisici che effettuano la suddetta trasformazione, o acquisizione.
Il più utilizzato di questi dispositivi è sicuramente lo scanner.
E’ possibile utilizzare lo scanner per acquisire: foto, disegni e pagine di documenti cartacei.
Il suo uso è molto semplice, basta appoggiare sul piano trasparente il foglio con l’immagine da acquisire rivolta verso il piano stesso, e attivare un apposito programma di acquisizione che ci guiderà nell’operazione.
Il programma di acquisizione, che viene sempre fornito assieme allo scanner, prima di utilizzarlo, andrà ovviamente installato.
Nell’ambito di quest’ultimo è importante la scelta della risoluzione con cui verrà acquisita l’immagine.
Questo importante parametro si esprime in DPI, ovvero dot per inch (punti per pollice).
Se il valore in DPI della risoluzione è troppo basso l’immagine prodotta risulterà poco dettagliata, mentre se è troppo alto c’è il rischio di produrre inutilmente dei file di grandi dimensioni.
Un valore generalmente appropriato per ottenere immagini di buona qualità è, ad esempio, 300 DPI, mentre per immagini da pubblicare sul web, e dove è importante evitare file eccessivamente pesanti, di solito si utilizza una risoluzione di soli 72 DPI.
Ciò che determina la qualità di uno scanner è:
- la massima risoluzione, e che come abbiamo visto si misura in DPI
- la massima risoluzione ottenuta per interpolazione, e che è un artificio software per accrescere fittiziamente la risoluzione
- la profondità di colore, e che ci dice quanti sono i colori utilizzati dallo scanner per descrivere ogni pixel
- il tipo di collegamento con il computer, e da cui dipende la velocità con cui possiamo scansionare una immagine (in genere conviene utilizzare collegamenti di tipo USB al posto dei più datati e lenti collegamenti su porta parallela)
- il programma di acquisizione (un programma troppo macchinoso rende tutto più complicato e ci farà perdere tempo e pazienza).
La fotocamera digitale
Sono dispositivi che acquisiscono un’immagine tramite una matrice attiva di pixel chiamata CCD.
Più pixel saranno presenti sul CCD, maggiore sarà la massima risoluzione dell’immagine prodotta dalla macchina fotografica.
Una macchina ad esempio con un CCD di 1 megapixel (circa 1 milione di pixel) sarà in grado di catturare immagini composte di circa 1000 pixel di lato.
Una immagine da stampare su carta, per essere di buona fattura, dovrà essere prodotta da un macchina fotografica con un CCD di almeno 2 megapixel.
Se invece interessa produrre immagini per il Web potremmo utilizzare sensori anche con meno di 1 megapixel.
Le foto, anziché su pellicola, sono conservate su di una particolare memoria che non cancella le immagini quando spegniamo la macchina fotografica.
Il numero di foto che è possibile conservare su questa memoria dipende dalla definizione delle foto e dalla capacità della memoria, insomma: più memoria più foto, più definizione meno foto.
In ogni caso, una volta riempita la memoria della fotocamera, dovremo trasferire il suo contenuto su di un computer per poterla cancellare e poi riutilizzare nuovamente.
Se si vuole usare la fotocamera durante i viaggi, e durante i quali non si ha a disposizione un computer, conviene allora acquistare una o più schede di memoria ausiliarie per non essere costretti a cancellare le foto già fatte quando la memoria a nostra disposizione è in via di esaurimento.
Per trasferire le foto dalla memoria della fotocamera al computer si usa normalmente una connessione di tipo USB, ma in alcuni modelli è possibile trovare al suo posto una porta seriale.
Anche ora un programma di acquisizione viene fornito assieme alla fotocamera digitale.
Con il suddetto programma si è in grado di:
- scaricare su di un computer le foto presenti nella memoria della macchina fotografica digitale
- organizzare su di un computer le foto all’interno di un album
- stampare le foto.
Per quest’ultima operazione una comoda alternativa può essere quella di utilizzare delle apposite stampanti in grado di stampare direttamente (senza passare per un computer) le immagini contenute nella memoria di una fotocamera digitale.
I formati grafici
Non è unico il modo in cui si può effettuare la codifica digitale di un’immagine.
Ciò comporta che ad un’unica immagine possono corrispondere più rappresentazioni digitali, ovvero più formati grafici.
Per riconoscere il tipo di formato in cui è stata codificata un’immagine basta osservare l’estensione del relativo file.
Quando un’immagine digitale è ottenuta da quella bitmap eliminando le informazioni visive meno importanti, si dice che l’immagine stessa è stata sottoposta a compressione con perdita.
Esistono differenti tipi di compressione con perdita, ma quello più utilizzato si chiama JPEG. Un file che contiene un’immagine compressa di quest’ultimo tipo ha l’estensione JPG, e può anche essere 100 volte più leggera dell’originale file bitmap.
Esiste anche la cosiddetta compressione senza perdite.
La compressione senza perdite, se applicata a immagini con molte variazioni cromatiche, comprime meno rispetto a quella JPEG, ed infatti presenta i seguenti vantaggi:
- risulta più adatta a rappresentare immagini geometriche dai contorni decisi e con poche sfumature dato che non elimina nulla durante la compressione
- consente di definire la trasparenza, ovvero possiamo definire come trasparente tutto ciò che è tra il bordo irregolare dell’immagine e il confine rettangolare del riquadro che la contiene.
Il formato più utilizzato per questo tipo di compressione si chiama GIF.
Il suo più grosso limite è che non consente di usare più di 256 colori all’interno di una singola immagine.
Il formato GIF è dunque comodo per loghi e marchi, ed è meno adatto per fotografie ed immagini con molte sfumature.
Usato più raramente è il formato senza perdite TIFF.
Presenta l’estensione TIF, è simile al GIF, ma non ha la limitazione dei colori fino a 256.
La grafica vettoriale
Non tutte le immagini sono disegni o fotografie.
Spesso, infatti, abbiamo a che fare anche con schemi o con grafici costruiti a partire da semplici figure geometriche.
In questi casi, invece di descrivere l’immagine pixel per pixel, conviene specificare: tipo, forma, colore, dimensione e posizione delle figure geometriche (cerchi, rettangoli, linee, frecce e così via) che la compongono.
Nel caso di un quadrato, ad esempio, potremmo limitarci a descrivere le coordinate dei quattro vertici del quadrato e la lunghezza di un suo lato, piuttosto che descriverne tutti i punti come avviene in una bitmap.
Tecnicamente il nome dell’immagine digitale appena descritta è quello di immagine vettoriale.
Semplici programmi di disegno vettoriale sono integrati all’interno di programmi come Word e PowerPoint, e consentono ad esempio di aggiungere rapidamente e con estrema facilità uno schema al testo che stiamo scrivendo.
Anche le immagini grafiche già pronte con l’estensione WMF che Word mette a disposizione, le cosiddette clipart, sono realizzate in grafica vettoriale.
I vantaggi della descrizione vettoriale sono essenzialmente tre:
- si risparmia sulle dimensioni dell’immagine dato che al posto della descrizione di tutti i punti basta specificare solo la posizione di pochi punti chiave
- si possono facilmente dare delle nuove dimensioni ad un’immagine
- si può facilmente muovere ogni singolo elemento geometrico che compone l’immagine.
INTRODUZIONE ALLA FOTOGRAFIA DIGITALE
Quando ci si mette alla ricerca della propria macchina fotografica digitale, si comincia ad avere a che fare con una serie di numeri e nuove unità di misura. Nella maggior parte dei casi, queste cifre esprimono la risoluzione della fotocamera, ovvero l'accuratezza con cui l'apparecchio e' in grado di delineare i dettagli. Ci sono però anche altre note sulle caratteristiche dell'apparecchio che possono essere complicate da interpretare a meno che non si abbia una certa conoscenza tecnica del mondo dei computer. Proviamo allora a capire cosa bisogna sapere per una consapevole valutazione di questi dati.
Risoluzione: Il dispositivo di ripresa di una fotocamera digitale e' composto da un incolonnamento di sensori che catturano il colore e le informazioni sulla luce, convertendoli poi elettricamente nel dato numerico che caratterizza ogni singolo pixel (dall'inglese "picture elements"). Se una fotocamera e' in grado di fotografare un immagine composta da 640 pixel orizontali e 480 pixel verticali, si dice che ha una risoluzione di 640 per 480, quindi 307200 pixels. Potendo raggruppare più pixel nella medesima area, si producono immagini con una risoluzione più elevata, ovvero con una maggiore qualità nei dettagli.
Oltre alla risoluzione ottica, presa in considerazione fino a questo momento, tra le caratteristiche tecniche descrittive di un particolare apparecchio, troviamo spesso la così detta risoluzione interpolata. L'interpolazione e' un artificio matematico realizzato dal software della fotocamera, che permette di incrementare la risoluzione andando ad aggiungere pixel di cui si stima il colore e la luminosità. Questo procedimento compromette comunque in qualche misura la resa qualitativa. L'interpolazione e' anche realizzabile attraverso l'uso dei più comuni programmi di fotoritocco, per cui nella maggior parte dei casi non e' consigliabile ricorrervi in fase di ripresa.
Risoluzione di stampa e risoluzione video: Addentriamoci a questo punto un po' più approfonditamente nella definizione del concetto di risoluzione e delle unità di misura in cui la risoluzione e' espressa. Questo argomento deve essere chiarito soprattutto per poter avere una buona consapevolezza dei risultati ottenibili con l'attrezzatura che ci si appresta ad acquistare.
Abbiamo detto che la risoluzione delle immagini digitali (così come quella dei monitor) e' espressa in pixel per pollice (pixel-per-inch - ppi). La risoluzione degli apparati di stampa e' invece espressa in punti per pollice (dot-per-pixel - dpi), ovvero in numero di punti di inchiostro che la stampante e' in grado di scrivere per ogni pollice di supporto. Capita spesso che le due unità di misura siano considerate equivalenti, il che genera indubbi errori di valutazione.
Supponiamo di acquisire un'immagine con un dispositivo avente una risoluzione pari a 640 per 480 pixels. Per capire quale sarà la dimensione di tale immagine nella sua rappresentazione a video, occorre prendere in considerazione la risoluzione del monitor utilizzato. Un'impostazione classica per i video corrisponde a 72 ppi. Consideriamo questo valore il parametro di riferimento e facciamo alcuni calcoli. Dividendo gli originali 640 punti per i 72 punti per pollice visualizzabili sul monitor, si ricava che l'immagine ha una lunghezza a video di 8,8 pollici (circa 22,4 cm). Applicando la stessa operazione alla misura dell'altezza si ottiene il valore di 6,6 pollici (circa 16,8 cm). Abbiamo in questo modo dedotto le dimensioni sul video.
Per quanto riguarda invece la stampa dell'immagine, il ragionamento da seguire e' leggermente diverso. In fase di stampa bisogna innanzi tutto decidere quale risultato stiamo cercando di perseguire: possiamo decidere di ottimizzare la resa qualitativa dell'immagine, oppure possiamo imporre che venga rispettata una determinata dimensione e accettare quella che sarà la qualità risultante. I due parametri sono inevitabilmente legati tra loro, in quanto maggiore e' il numero di punti di inchiostro che dedichiamo ad ogni pixel (aumentando di conseguenza le dimensioni), e peggiore è la qualità del risultato finale. Procedendo in questa maniera infatti si rende progressivamente più evidente il fatto che l'immagine è composta da una serie di quadratini di inchiostro colorato.
La qualità della stampa può essere considerata ottima nel caso in cui ad ogni pixel venga fatto corrispondere un punto di inchiostro. Supponiamo di avere a disposizione una stampante con una risoluzione di 360 dpi. L'immagine presa in considerazione prima, che sul monitor (essendo espressa su di una matrice di 72 punti per pollice lineare), appariva di dimensioni pari a 8,8 per 6,6 pollici, risulta su carta di 1,7 per 1,3 pollici (4,13 per 3,5 cm), in quanto, stampando 360 punti di inchiostro per pollice, occorrono rispettivamente 1,7 e 1,3 pollici di supporto per stampare i 640 per 480 pixel che la compongono.
Se vogliamo invece mantenere la dimensione dell'immagine tale quale appariva sul monitor, occorre diminuire la risoluzione di stampa: dedicando 5 punti di inchiostro ad ogni pixel di immagine, si mantiene su carta l'originaria risoluzione video di 72 ppi e si mantengono quindi anche le dimensioni. In questo caso un buon suggerimento per migliorare la qualità, è quello di provare ad aumentare la risoluzione a video mediante il procedimento dell'interpolazione.
Messa a fuoco e Zoom: Soltanto le fotocamere digitali di fascia alta sono dotate di obbiettivi con messa a fuoco variabile. Tuttavia, essendo la lunghezza focale delle fotocamere compatte molto ridotta, la profondità di campo e' sempre tale da garantire una messa a fuoco perfetta a partire da una certa distanza minima fino ad arrivare ad infinito. Nelle fotografie in cui il soggetto e' particolarmente prossimo all'obbiettivo, e' sufficiente assicurarsi delle normali condizioni di illuminazione per ottenere dei buoni risultati. Per quanto riguarda invece lo zoom, e' necessario ancora distinguere tra zoom ottico e zoom digitale. Lo zoom ottico, e' in tutto simile allo zoom delle macchine fotografiche classiche. Lo zoom digitale e' invece ottenuto grazie ad un procedimento matematico attraverso il quale si isola la zona dei sensori fotosensibili coinvolti nella ripresa del particolare dell'immagine di proprio interesse, e si riporta la risoluzione dell'immagine al valore massimo mediante l'interpolazione. Di conseguenza la qualità finale dell'immagine ne risente in maniera proporzionale all'ingrandimento eseguito. Lo zoom ottico e' quindi senza dubbio il migliore, mentre lo zoom digitale e' una buona risorsa a cui ricorrere soltanto se si sta fotografando per pubblicare su Web o comunque su monitor. Eseguire uno zoom digitale in fase di ripresa equivale a ritagliare il particolare di una foto con un programma di fotoritocco e poi ingrandirlo.
La memorizzazione delle immagini: Nella fotografia digitale il rullino non è più utilizzato, ed e' sostituito da supporti in grado di memorizzare i valori numerici che descrivono le immagini riprese e che ne permettono la ricostruzione nel pc. Tali supporti sono in pratica delle carte di memoria simile a quelle presenti nei computer. Esse possono essere integrate nella macchina fotografica, o possono essere removibili. Nel caso in cui siano integrate, il trasferimento dei dati tra la fotocamera e il computer avviene tramite un cavo seriale. In questo caso una buona stima del tempo di attesa necessario per il trasferimento di ogni foto e' di 30 secondi. Se si considera quindi che per trasferire trenta immagini occorrono, secondo queste tempistiche, quindici minuti, si capisce che il procedimento può diventare piuttosto tedioso. Le carte removibili hanno il vantaggio di diminuire questi tempi di attesa e di mettere a disposizione una memoria più capiente. Due sono i modelli che si possono annoverare tra gli standard: la Compact Flash e la Smart Media. La SmartMedia in particolare, grazie all'uso di un adattatore, può molto comodamente essere inserita in un comune lettore di floppy disk, permettendo così un pregevole portabilità. Nel caso la propria fotocamera sia equipaggiata con memorie removibili, nulla vieta in oltre di acquistarne alcune di scorta da portare sempre con se, così come siamo usi fare con le macchine fotografiche classiche ed i comuni rullini.
Il formato delle immagini: Alcune caratteristiche relative al formato delle immagini digitali vanno prese in considerazione nel momento in cui si decide di archiviare le proprie fotografie. Chi ha un po' di pratica con i programmi di fotoritocco, certamente sa che ogni software per l'elaborazione delle immagini e' in grado di salvare i dati in un formato proprietario. Infatti, negli anni in cui la grafica digitale andava affermandosi, abbiamo assistito ad una corsa, da parte dei produttori di hardware o di software, per l'ideazione della struttura dati più adatta alla memorizzazione delle immagini. Con il passare del tempo, e' tuttavia risultato evidente, che il concetto di formato proprietario doveva essere superato, in quanto sempre più spesso l'utente si trovava di fronte all'esigenza di portare le proprie immagini da una piattaforma all'altra o da un programma all'altro. Così oggi, ogni software di fotoritocco supporta, oltre all'eventuale formato proprietario, anche tutti gli altri formati più diffusi. I più comuni sono: Tiff, Jpeg, Gif.
Il formato Tiff (Tag Image File Format) e' stato sviluppato dalla Aldus Corporation nel 1986 ed e' il formato più versatile attualmente in utilizzo. Supporta infatti qualunque tipo di immagine, con qualunque profondità cromatica ed e' dotato di alcune specifiche per la compressione dei dati. L'unico inconveniente e' che, essendo disponibile in diverse versioni, può capitare che una particolare applicazione incorra in qualche problema nell'importare un'immagine salvata con un differente programma.
Il Jpeg (Joint Photographics Experts Group) non e' un vero e proprio formato di memorizzazione delle immagini, ma piuttosto un meccanismo di codifica dei dati usato per ridurre la dimensione dei file. E' nativamente applicato ad immagini in formato Tiff, e ne permette la compressione fino ad un fattore di circa 15 volte. Non e' da usare durante un procedimento di fotoritocco in quanto ogni qualvolta l'immagine viene salvata si ha una perdita di dettagli non visibili che assume però un peso non indifferente sulle eventuali successive operazioni di correzione cromatica.
Il Gif (Graphics Interchange Format) e' stato sviluppato dalla CompuServe nel 1987 esplicitamente con l'obbiettivo di realizzare un formato leggero adatto al trasferimento delle immagini su canali multimediali. Il limite maggiore nell'implementazione di programmi software che utilizzano questo formato e' costituito dal fatto che utilizza un algoritmo proprietario (LZW) per l'utilizzo del quale e' necessario acquistare la licenza dall' IBM. Questo e' tuttavia un inconveniente per la realizzazione dei software che ambiscono a gestire anche questo formato, non certo per l'utente che si avvale di un tale programma.
Naturalmente esistono moltissimi altri formati quali ad esempio l'Eps o il Pict, ma non è il caso di addentrarsi ulteriormente nella descrizione dei dettagli.
Consumo energetico: Uno degli argomenti più accattivanti in grado di convincere gli scettici ad acquistare una macchina fotografica digitale, riguarda il fatto, che superato l'investimento iniziale per l'attrezzatura, non si dovranno più sostenere spese per lo sviluppo e la stampa delle pellicole. Tuttavia, i costi di mantenimento del proprio hobby, vengono completamente annullati soltanto se si ha l'accortezza di dotarsi di batterie ricaricabili. Molti modelli di fotocamera digitale ne sono naturalmente dotati, e vengono quindi venduti accessoriati con il relativo carica batterie. Se comunque così non fosse, il consiglio è quello di sostituire le pile stilo usa e getta di comune utilizzo, con pile ricaricabili. L'investimento sarà ripagato in un breve periodo in quanto il consumo di energia delle fotocamere digitali non è indifferente.
Lineatura (l.p.i. line per inch.)
Livello di finezza della trama dell'immagine espressa in linee per pollice o per centimetro.
Es.: 150 linee per pollice che corrispondono a 59 linee al cm2
(misura italiana).
Fonte: http://www.marforio.org/appunti/sistemadielaborazionedelleinformazioni/La%20digitalizzazione%20delle%20immagini.doc
Autore del testo: non indicato nel documento di origine
Guida alla fotografia digitale
Visita la nostra pagina principale
Guida alla fotografia digitale
Termini d' uso e privacy